Kurzfassung
- ARC-AGI-3 offenbart eine enorme Kluft zwischen den Behauptungen zu AGI und der Realität: Top-AI-Modelle erzielen weniger als 1 %, während Menschen perfekte Leistungen erbringen.
- Der Benchmark testet echtes Generalisieren – erfordert, dass Agenten in unbekannten Umgebungen erkunden, planen und aus dem Nichts lernen, anstatt trainierte Muster abzurufen.
- Trotz Branchenhype sind aktuelle KI-Systeme weit von AGI entfernt, ihnen fehlen das logische Denken und die Anpassungsfähigkeit, die selbst junge Menschen natürlich zeigen.
Nvidia-CEO Jensen Huang war letzte Woche im Lex Fridman-Podcast und sagte ganz offen: „Ich denke, wir haben AGI erreicht.“ Zwei Tage später veröffentlichte die rigoroseste KI-Studie den neuesten Benchmark für künstliche Allgemeinintelligenz – und alle Top-Modelle erreichten weniger als 1 %.
Die ARC Prize Foundation veröffentlichte diese Woche ARC-AGI-3, und die Ergebnisse sind brutal. Google’s Gemini 3.1 Pro führte mit 0,37 %. OpenAI’s GPT-5.4 kam auf 0,26 %. Anthropic’s Claude Opus 4.6 erreichte 0,25 %, während xAI’s Grok-4.20 genau null Punkte erzielte. Menschen lösten dagegen 100 % der Umgebungen.
Dies ist kein Trivia-Test, kein Programmier-Examen oder gar hochkomplexe PhD-Fragen. ARC-AGI-3 ist etwas völlig Neues, mit dem die KI-Branche noch nie konfrontiert war.
Der Benchmark wurde von François Chollet und der Mike Knoop Foundation entwickelt, die ein internes Spieestudio eingerichtet und 135 originale interaktive Umgebungen von Grund auf geschaffen haben. Ziel ist es, eine KI in eine unbekannte, spielähnliche Welt ohne Anweisungen, Ziele oder Regeln zu setzen. Die KI muss erkunden, herausfinden, was sie tun soll, einen Plan entwickeln und ausführen.
Wenn das klingt, als könnte es jedes fünfjährige Kind, beginnt man, das Problem zu verstehen. Wenn du testen willst, ob du besser bist als die KI, kannst du die gleichen Spiele, die im Test verwendet werden, über diesen Link spielen. Wir haben eines ausprobiert; es war anfangs seltsam, aber nach ein paar Sekunden hast du den Dreh raus.
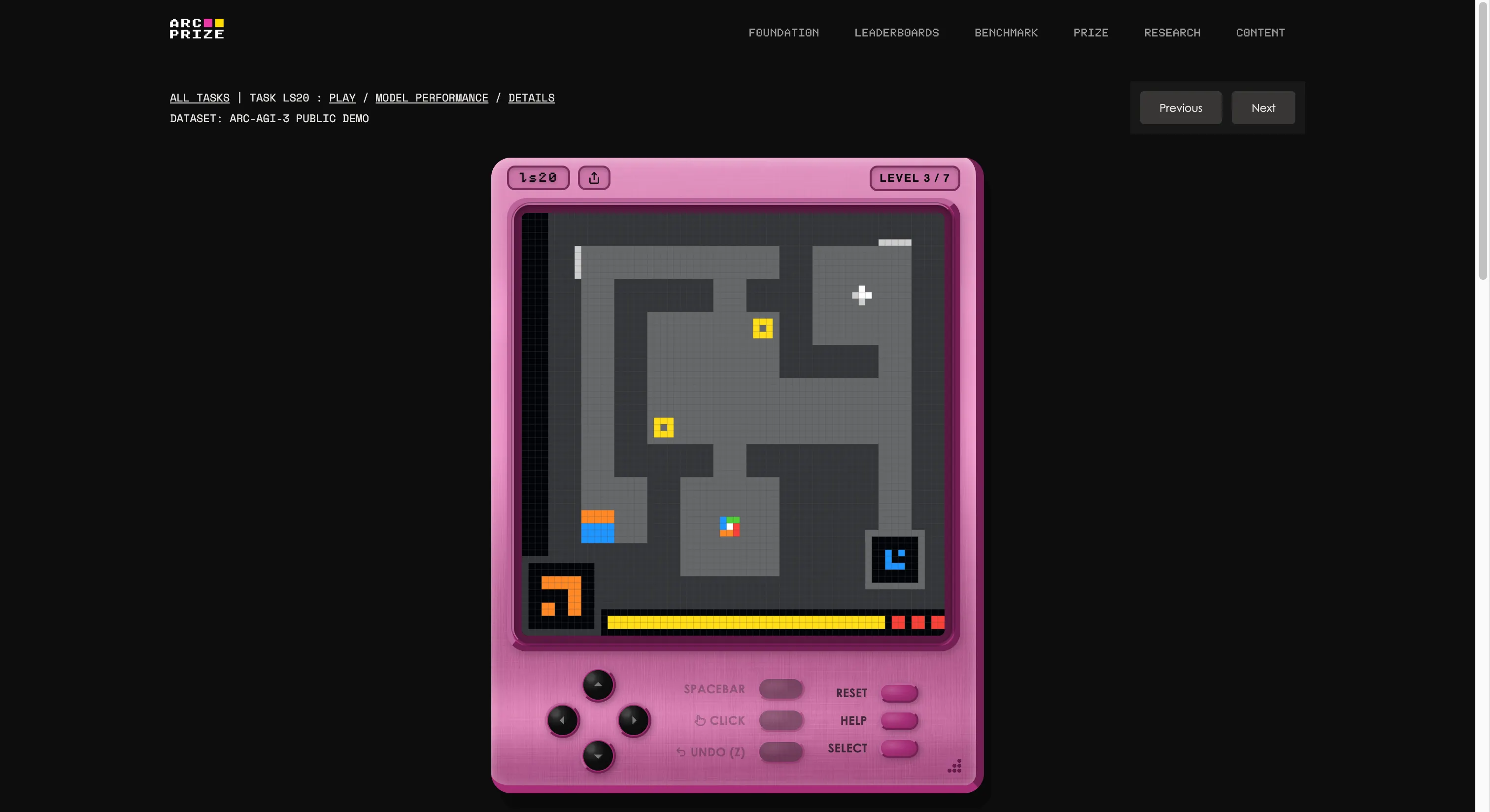
Es ist auch das klarste Beispiel dafür, wofür das „G“ in AGI steht. Beim Generalisieren kannst du neues Wissen schaffen (wie ein seltsames Spiel funktioniert), ohne vorher darauf trainiert worden zu sein.
Frühere Versionen von ARC testeten statische visuelle Rätsel – Muster zeigen, das nächste vorhersagen. Anfangs waren sie schwer. Dann setzten die Labore Rechenleistung und Training ein, bis die Benchmarks praktisch tot waren. ARC-AGI-1, eingeführt 2019, basierte auf Testzeit-Training und reasoning-Modellen. ARC-AGI-2 hielt etwa ein Jahr, bevor Gemini 3.1 Pro 77,1 % erreichte. Die Labore sind sehr gut darin, Benchmarks zu sättigen, gegen die sie trainieren können.
Version 3 wurde speziell entwickelt, um das zu verhindern. Mit 110 der 135 Umgebungen privat gehalten – 55 halb-privat für API-Tests, 55 vollständig gesperrt für Wettbewerbe – gibt es keinen Datensatz, den man auswendig lernen könnte. Man kann sich durch neuartige Spiel-Logik nicht mit brute-force Methoden durchmogeln.
Das Ergebnis wird auch nicht als Bestehen/Nichtbestehen bewertet. ARC-AGI-3 verwendet, was die Foundation RHAE nennt – Relative Human Action Efficiency. Die Basis ist die zweitbeste, erste menschliche Leistung bei einem Durchlauf. Eine KI, die zehnmal so viele Aktionen braucht wie ein Mensch, erhält für diese Ebene 1 %, nicht 10 %. Die Formel quadriert die Strafe für Ineffizienz. Herumirren, zurückgehen und raten, wird hart bestraft.
Der beste KI-Agent im einmonatigen Entwickler-Preview erreichte 12,58 %. Frontier-LLMs, getestet über die offizielle API ohne eigene Tools, konnten nicht einmal 1 % knacken. Normale Menschen lösten alle 135 Umgebungen ohne vorheriges Training und ohne Anweisungen. Wenn das die Messlatte ist, schaffen es die aktuellen Modelle nicht.
Hier gibt es eine echte methodische Debatte. Der Bericht von ARC sagt, ein von Duke entwickeltes, maßgeschneidertes System habe Claude Opus 4.6 von 0,25 % auf 97,1 % in einer einzelnen Variante namens TR87 gehoben. Das bedeutet nicht, dass Claude insgesamt 97,1 % bei ARC-AGI-3 erreichte; sein offizieller Benchmark-Wert blieb bei 0,25 %, aber die Veränderung ist dennoch bemerkenswert.
Der offizielle Benchmark liefert Agenten JSON-Code, keine Visuals. Das ist entweder ein methodischer Fehler oder ein Beweis dafür, dass heutige Modelle besser darin sind, menschenfreundliche Informationen zu verarbeiten als rohe, strukturierte Daten. Chollet’s Foundation hat die Debatte anerkannt, ändert aber nichts am Format.
„Frame Content Perception und API-Format sind keine limitierenden Faktoren für die Leistung von Top-Modellen bei ARC-AGI-3“, heißt es im Bericht. Mit anderen Worten, sie lehnen die Idee ab, dass Modelle scheitern, weil sie die Aufgaben „nicht richtig sehen“; vielmehr sei die Wahrnehmung bereits ausreichend – die eigentliche Lücke liegt im reasoning und Generalisieren.
Der Reality-Check zu AGI kam in einer Woche, in der die Hype-Maschine auf Hochtouren lief. Neben Huangs Kommentar hat Arm seinen neuen Rechenzentrum-Chip „AGI CPU“ genannt. OpenAI’s Sam Altman sagte, sie hätten „quasi AGI gebaut“, und Microsoft vermarktet bereits ein Labor, das sich auf den Bau von ASI konzentriert: einer Evolution dessen, was nach Erreichen von AGI kommt. Der Begriff wird so weit gedehnt, bis er bedeutet, was auch immer kommerziell praktisch ist.
Chollet’s Position ist einfacher. Wenn ein normaler Mensch ohne Anweisungen es kann und dein System nicht, hast du kein AGI – sondern eine sehr teure Autovervollständigung, die viel Hilfe braucht.
Der ARC-Preis 2026 bietet 2 Millionen Dollar in drei Wettbewerbs-Tracks, alle auf Kaggle ausgetragen. Jede Gewinnerlösung muss Open Source sein. Die Zeit läuft, und momentan sind die Maschinen noch weit entfernt.
Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.
