Alat AI CanIRun.ai dapat secara otomatis mendeteksi spesifikasi perangkat keras pengguna melalui browser, dan memperkirakan model LLM apa yang dapat dijalankan serta kecepatan inferensinya. Pengguna yang tertarik dapat mencoba dan mempelajarinya.
(Latar belakang: Clawdbot yang menjadi legenda, sebuah AI pengelola 24 jam yang membuat Mac mini kehabisan stok)
(Informasi tambahan: Jangan ikut-ikutan OpenClaw secara membabi buta, AI Udang Air Panas sangat kuat, tapi belum tentu cocok untukmu)
Daftar Isi Artikel
Toggle
- Kekurangan kecil CanIRun.ai
- Alternatif command line, llmfit, hadir
- Yang paling diinginkan komunitas
Apakah kamu ingin menginstal model bahasa besar (LLM) secara lokal di perangkatmu sendiri? Pertanyaan pertama yang paling sering dihadapi pemula adalah: Komputer saya, model apa saja yang bisa dijalankan? Artikel ini akan memperkenalkan sebuah alat yang baru-baru ini memicu diskusi di komunitas Hacker News, yaitu CanIRun.ai.
CanIRun.ai adalah sebuah alat berbasis web murni, sangat mudah digunakan: cukup buka browser, dan secara otomatis akan mendeteksi model GPU dan spesifikasi memorinya melalui WebGPU API. Selanjutnya, berdasarkan jumlah parameter model, tingkat kuantisasi (Q4_K_M, Q8_0, F16, dll), serta bandwidth memori, alat ini akan memperkirakan kelayakan menjalankan model tersebut dan kecepatan inferensinya (token/detik), lalu menampilkan hasilnya dengan penilaian dari tingkat S sampai F.
Cakupan model mulai dari yang sangat ringan dengan 0,8 miliar parameter, hingga model MoE (Mixture of Experts, arsitektur campuran pakar) raksasa dengan 1 triliun parameter. Sumber data berasal dari alat inferensi lokal utama seperti llama.cpp, Ollama, dan LM Studio.
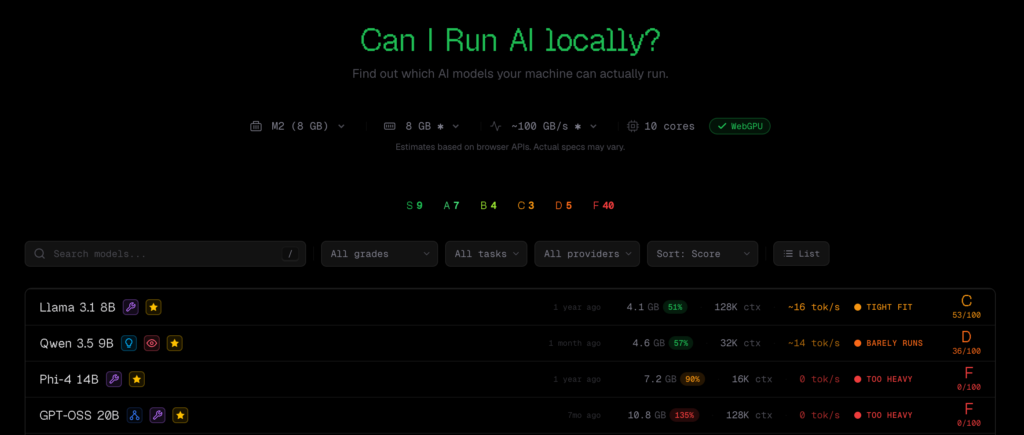
Kekurangan kecil CanIRun.ai
Meskipun konsep alat ini mendapatkan pengakuan positif dari komunitas, ada beberapa kritik yang muncul. Fokus utama terletak pada dua aspek: cakupan perangkat keras yang tidak lengkap dan ketidaksesuaian hasil estimasi dengan pengujian nyata.
Daftar perangkat keras yang tidak tercantum sering menjadi masalah yang paling sering disebutkan. GPU seperti RTX Pro 6000, RTX 5060 Ti 16GB, serta berbagai GPU laptop saat ini belum tercantum. Untuk chip Apple, meskipun sudah dicantumkan, hanya sampai konfigurasi memori 192GB, padahal M3 Ultra sebenarnya mampu mendukung hingga 512GB.
Masalah ketidaktepatan estimasi juga muncul ketika hasil pengujian pengguna tidak sesuai dengan prediksi CanIRun.ai. Kasus seperti “dapat dijalankan secara nyata tetapi situs mengatakan tidak” sering muncul dalam diskusi, sehingga beberapa pengguna memutuskan untuk tidak mengandalkan hasilnya.
Meskipun situs ini masih bisa diperbaiki di banyak aspek, bagi pemula atau orang awam, alat ini tetap bisa membantu dengan cepat memastikan perangkat mereka.
Alternatif command line, llmfit, hadir
Selain itu, ada yang merekomendasikan alat pengganti bernama llmfit: sebuah program command line yang dapat langsung memanggil alat sistem (termasuk nvidia-smi) untuk mendapatkan informasi GPU secara akurat, tanpa bergantung pada API browser. Banyak yang menganggap bahwa llmfit lebih praktis dan lebih akurat dibandingkan versi web.
Namun, llmfit juga menimbulkan diskusi lain: ada pengguna yang terkejut karena alat ini mampu mengenali model GPU secara tepat tanpa meminta izin khusus. Hal ini menyentuh sensitivitas komunitas terhadap fingerprint browser dan privasi perangkat keras: jika sebuah alat web dapat mendeteksi kartu grafis melalui WebGPU API, bagaimana data tersebut akan digunakan?
Ada pengguna yang menyarankan bahwa fungsi semacam ini sebaiknya langsung diintegrasikan ke dalam Ollama, sehingga pengguna bisa secara otomatis memilih model yang sesuai berdasarkan perangkat keras mereka dari command line, tanpa perlu pencarian manual.
Yang paling diinginkan komunitas
Berdasarkan umpan balik dari komunitas, batasan utama dari CanIRun.ai saat ini bukan hanya pada ketepatan estimasi, tetapi juga pada satu dimensi penilaian yang terlalu sederhana. Pengguna sebenarnya ingin tahu: di perangkat mereka, model mana yang terbaik dari segi kualitas dan kecepatan yang dapat diterima? Saat ini, alat ini hanya bisa menjawab “bisa dijalankan” atau tidak, tetapi tidak bisa menjawab “cukup bagus untuk dijalankan?”
Komunitas berharap ke depan akan ada penambahan penilaian kemampuan model yang menggabungkan estimasi perangkat keras, sehingga memberikan dasar pilihan yang lebih lengkap. Selain itu, ada juga keinginan untuk perbaikan teknis seperti: memasukkan strategi berbagi memori CPU (agar GPU yang kekurangan memori bisa meminjam dari memori sistem), mendukung teknik offloading KV cache, dan memperbaiki logika perhitungan model MoE.
Secara keseluruhan, arah pengembangan alat ini sudah tepat dan kebutuhan pasar memang ada: hambatan untuk AI lokal masih cukup tinggi bagi pengguna umum, dan kemampuan untuk dengan cepat mengetahui “apa yang cocok dijalankan di mesin saya” adalah kebutuhan mendesak. CanIRun.ai menyentuh titik ini, meskipun masih membutuhkan penyempurnaan lebih lanjut.

Penafian: Informasi di halaman ini dapat berasal dari pihak ketiga dan tidak mewakili pandangan atau opini Gate. Konten yang ditampilkan hanya untuk tujuan referensi dan bukan merupakan nasihat keuangan, investasi, atau hukum. Gate tidak menjamin keakuratan maupun kelengkapan informasi dan tidak bertanggung jawab atas kerugian apa pun yang timbul akibat penggunaan informasi ini. Investasi aset virtual memiliki risiko tinggi dan rentan terhadap volatilitas harga yang signifikan. Anda dapat kehilangan seluruh modal yang diinvestasikan. Harap pahami sepenuhnya risiko yang terkait dan buat keputusan secara bijak berdasarkan kondisi keuangan serta toleransi risiko Anda sendiri. Untuk detail lebih lanjut, silakan merujuk ke
Penafian.