À medida que as cargas de trabalho de inferência migram de clusters de teste para aplicações empresariais reais, a solução padrão ideal deixa de ser “tudo centralizado em data centers de ultra grande escala”. Este artigo analisa a lógica em camadas de nós de borda, data centers regionais e clusters centrais sob as óticas de latência, largura de banda, disponibilidade e conformidade. Apresenta pontos críticos sobre particionamento de tarefas, fronteiras de dados e governança operacional em topologias híbridas, além de comparar com a cadeia mais ampla de infraestrutura de IA.
No discurso público, costuma-se associar poder de hash de IA a “data centers de ultra grande escala e GPUs de alto desempenho”. Para treinamento e certos cenários de inferência centralizada, essa definição é geralmente válida. Infraestrutura de IA envolve solicitações de inferência amplamente distribuídas, sensíveis à latência e que exigem que os dados permaneçam dentro do domínio, sendo inaceitáveis interrupções de rede ou picos de congestionamento. Nesses casos, a topologia de inferência se torna uma questão de infraestrutura: o poder de hash precisa estar disponível e posicionado “no local geográfico e na camada de rede corretos”.
Se considerarmos a infraestrutura de IA como uma cadeia contínua, do nível do chip até serviços e governança, este artigo se concentra em topologia e formas de implantação: como distribuir computação e dados entre as camadas de borda, regionais e centrais para equilibrar latência, custo, disponibilidade e conformidade. Temas como energia, empacotamento e HBM pertencem a análises do lado da oferta, enquanto detalhes de roteamento multi-modelo corporativo e governança de agentes complementam operações produtivas.
Por que discutir “topologia de inferência distribuída”
A inferência centralizada proporciona operações unificadas, escalabilidade flexível e alta utilização de recursos. Porém, quando o negócio apresenta qualquer das seguintes características, as decisões topológicas impactam fortemente experiência e custo:
-
Restrições rigorosas de latência: Controle industrial, interação em tempo real, links de áudio/vídeo e pontos de venda offline são sensíveis à latência de cauda; trajetos de retorno extensos amplificam o jitter.
-
Soberania e residência de dados: Situações que envolvem informações pessoais, transações financeiras, serviços governamentais ou saúde geralmente exigem que os dados permaneçam no domínio, dentro das fronteiras ou em regiões específicas.
-
Largura de banda de retorno e custo: Pontos finais em massa enviam dados brutos continuamente para inferência central, tornando taxas de backbone e de saída potenciais principais fontes de custo.
-
Disponibilidade e resiliência: Em cenários de falha de rede de longa distância, oscilações de DNS ou congestionamento entre regiões, arquiteturas puramente centrais ficam mais vulneráveis a riscos em cascata de “indisponibilidade total”.
-
Rede offline ou limitada: Ambientes como minas, embarcações e fábricas exigem operação local, sem depender totalmente de conectividade online em tempo real.
Esses desafios não se resolvem apenas com “modelos centrais mais robustos”, pois o cerne está na distância física, nos caminhos de rede e nos limites regulatórios — não no pico de poder de hash de uma única inferência.
Implantação em camadas: o que resolvem as camadas de borda, regionais e centrais
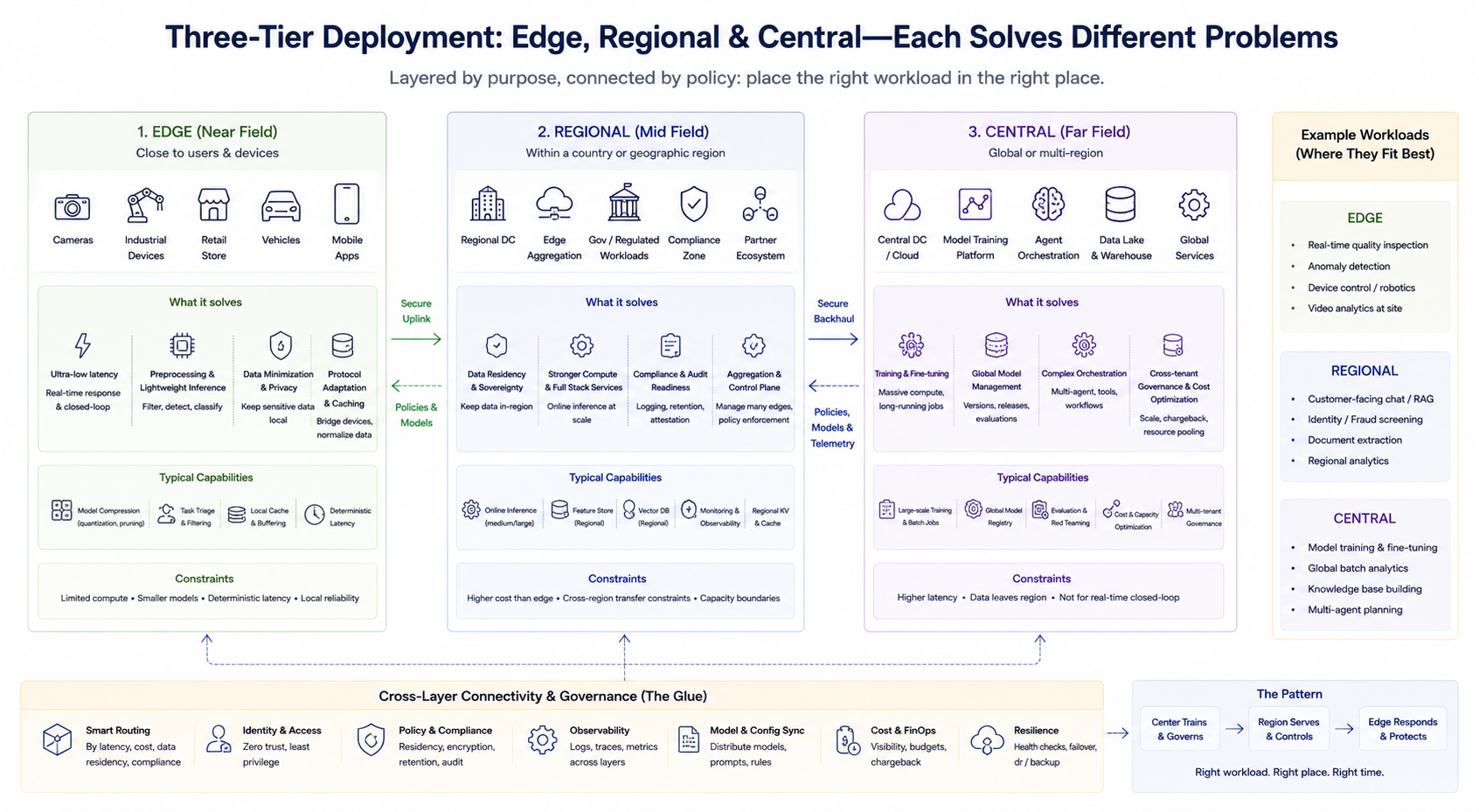
A abordagem de engenharia não é binária, mas sim uma combinação em camadas. Uma estrutura simplificada esclarece as responsabilidades de cada camada (a nomenclatura pode variar conforme o provedor):
Camada de borda (campo próximo)
Localizada próxima a usuários ou dispositivos, essa camada executa pré-processamento de baixa latência, inferência leve, cache e adaptação de protocolos. Ideal para loops fechados em tempo real e para minimizar uploads de dados sensíveis. O poder de hash é limitado, destacando-se compressão de modelos, poda de tarefas e latência determinística.
Camada regional (campo intermediário)
Oferece maior poder de hash e stack de serviços mais completo em países ou regiões específicas, atendendo residência de dados, auditoria de conformidade e necessidades de inferência agregada de médio porte. Também atua como plano de agregação e controle de múltiplos nós de borda.
Camada central (campo distante)
Gerencia treinamento, processamento em lote de grande escala, gestão global de modelos, orquestração de agentes complexos, governança unificada entre locatários e otimização de custos. É indicada para cargas menos sensíveis à latência, mas que demandam alto poder de hash e agregação de dados.
Essas camadas não são hierarquias rígidas, mas sim divisões por tarefa de negócio. Empresas podem operar simultaneamente treinamento central, inferência online regional e detecção em tempo real na borda, roteando solicitações conforme estratégias de roteamento.
Particionamento de tarefas: o que fica na borda, o que retorna ao centro
Os princípios de particionamento giram em torno de quatro eixos: minimização de dados, orçamento de latência, complexidade do modelo e frequência de atualização.
Tarefas ideais para a borda (considerando o poder de hash necessário):
-
Extração de características em tempo real, detecção de objetos, inspeção de qualidade e outros loops fechados de baixa latência
-
Inferência leve após dessensibilização local (por exemplo, envio apenas de vetores de características em vez de mídia bruta)
-
Estratégias de fallback e acerto de cache em redes fracas
Tarefas ideais para o centro ou região:
-
Fluxos de trabalho de agentes com contexto amplo, modelos robustos, toolchains complexas ou orquestração multi-sistema
-
Inferência analítica que demanda agregação de dados entre departamentos
-
Chamadas sensíveis que exigem auditoria centralizada e gestão unificada de chaves
Erros comuns incluem forçar grandes modelos com contexto longo para a borda, levando a OOM, ou enviar loops de baixa latência ao centro, prejudicando o ritmo produtivo. O objetivo da topologia não é “quanto mais borda, melhor”, mas sim alocar a carga certa no local correto, dentro das restrições.
Exigências de soberania de dados alteram diretamente a forma de implantação da inferência. Modelos podem ser baixados localmente, mas logs, caches, índices vetoriais e rastreamentos de chamadas ainda podem gerar riscos de conformidade. Perguntas críticas incluem:
-
Quais dados precisam ser armazenados e processados na borda ou camada regional
-
Quais metadados podem sair da região ou ir para a nuvem, e se há necessidade de anonimização e períodos de retenção
-
Se é permitido o uso entre regiões de versões e fornecedores de modelos diferentes (evitando “desvio de conformidade”)
-
Se, em auditorias e perícias, é possível reconstruir a saída como “gerada em determinado local, horário e com base em fragmentos de dados específicos”
As respostas a essas questões geralmente determinam a viabilidade de entrada em produção, mais do que “o modelo ser open source”. Ou seja, conformidade não é acessório para inferência de borda, mas condição fundamental para o design topológico.
Rede, energia e operações: os verdadeiros custos da implantação distribuída
A inferência distribuída implica custos sistêmicos que precisam ser avaliados com clareza no planejamento:
-
Rede: Com o aumento de nós de borda e regionais, cresce a complexidade de gestão de certificados, linhas dedicadas/SD-WAN, DNS e agendamento de tráfego. A latência de cauda é mais difícil de controlar em multipath.
-
Energia e data centers: Pontos de borda são dispersos, e a eficiência energética e refrigeração por unidade de poder de hash podem ser inferiores às de grandes data centers; data centers regionais ficam no meio-termo. O ritmo de entrega de energia e racks a montante ainda limita a expansão, mas o gargalo passa de “um único campus” para “múltiplos pontos paralelos”.
-
Operações e consistência de versões: Com modelos, prompts, estratégias de roteamento e índices liberados em múltiplos pontos, pode haver desvio de versões. Pipelines unificados de liberação, estratégias de rollback e verificações de integridade são necessários, ou os custos de troubleshooting anulam rapidamente os ganhos de latência da borda.
-
Expansão do escopo de segurança: Mais nós significam mais certificados, pontos de entrada e mídias de armazenamento locais. A segurança física e os ciclos de patch na borda costumam ser mais frágeis do que em data centers centrais, exigindo estratégias específicas de privilégio mínimo e controle remoto.
Portanto, topologia distribuída não é apenas “empurrar poder de hash para a borda”, mas transferir parte da complexidade operacional e de governança para mais perto do negócio. Se as capacidades organizacionais e as ferramentas de plataforma não acompanharem, os benefícios topológicos dificilmente se concretizam.
A maioria das soluções maduras adota arquiteturas híbridas: o centro cuida de treinamento, políticas globais e cargas pesadas; a região atende serviços online em zonas de conformidade; a borda lida com baixa latência e resiliência local. Padrões comuns incluem:
-
Cache em camadas e reutilização de resultados: a borda atende solicitações frequentes, e os misses são encaminhados ao centro. Chaves de cache, TTL e políticas de dados sensíveis devem ser definidos.
-
Divisão de modelos e pequenos modelos na borda: a borda executa modelos pequenos de detecção ou classificação, o centro faz fusão de grandes modelos e geração de interpretações (avaliado por cenário).
-
Retorno assíncrono e agregação: a borda toma decisões em tempo real e retorna amostras dessensibilizadas ou métricas de forma assíncrona para iteração e monitoramento de modelos.
-
Plano de controle unificado: roteamento, cotas, monitoramento e gestão de chaves são centralizados sempre que possível, com execução descentralizada, reduzindo o risco de “cada borda como uma ilha isolada”.
O segredo das arquiteturas híbridas bem-sucedidas está no plano de controle unificado aliado à execução em camadas — não apenas no aumento do número de nós.
Conclusão
A essência das discussões sobre inferência de borda e distribuída não é um “slogan de descentralização”, mas sim decisões técnicas entre latência, largura de banda, conformidade e custo operacional. À medida que o negócio evolui do demo para a escala, as escolhas topológicas moldam modelos, arquiteturas de rede e processos organizacionais. Ignorar essa camada pode resultar em forte poder de hash central, mas instabilidade persistente na linha de frente.









