Вкратце
- ARC-AGI-3 выявляет огромный разрыв между заявлениями об AGI и реальностью: лучшие модели ИИ показывают менее 1%, в то время как человек достигает идеальной производительности.
- Тест проверяет истинную обобщающую способность — требуя от агентов исследовать, планировать и учиться с нуля в неизвестных средах, а не просто воспроизводить обученные шаблоны.
- Несмотря на индустриальный хайп, текущие системы ИИ далеки от AGI, им не хватает логического мышления и адаптивности, которые даже у молодых людей проявляются естественно.
Генеральный директор Nvidia Дженсен Хуанг на прошлой неделе заявил в подкасте Лекса Фридмана: «Я считаю, что мы достигли AGI». Через два дня самый строгий тест в области ИИ опубликовал свой новый бенчмарк искусственного общего интеллекта — и все передовые модели показали менее 1%.
Фонд ARC Prize выпустил ARC-AGI-3 на этой неделе, и результаты оказались жесткими. Лидером стал Google Gemini 3.1 Pro с 0,37%. OpenAI GPT-5.4 набрал 0,26%. Anthropic Claude Opus 4.6 — 0,25%, а xAI Grok-4.20 — ровно ноль. В то же время, люди решили 100% задач.
Это не викторина или тест по программированию, и даже не сложные вопросы уровня PhD. ARC-AGI-3 — это совершенно иной вызов, чем что-либо, с чем сталкивалась индустрия ИИ раньше.
Тест был создан Фрэнсуа Шолле и Майком Кнопом, основателями фонда, которые организовали внутреннюю игровую студию и создали 135 оригинальных интерактивных сред с нуля. Идея — поместить ИИ-агента в незнакомый игровой мир без инструкций, целей или описания правил. Агент должен исследовать, понять, что от него требуется, сформировать план и выполнить его.
Если это звучит так, будто любой пятилетний справится, вы начинаете понимать проблему. Хотите проверить, лучше ли вы ИИ? Тогда можете поиграть в те же игры, что и в тесте, перейдя по этой ссылке. Мы попробовали одну — сначала было странно, но через несколько секунд стало понятно.
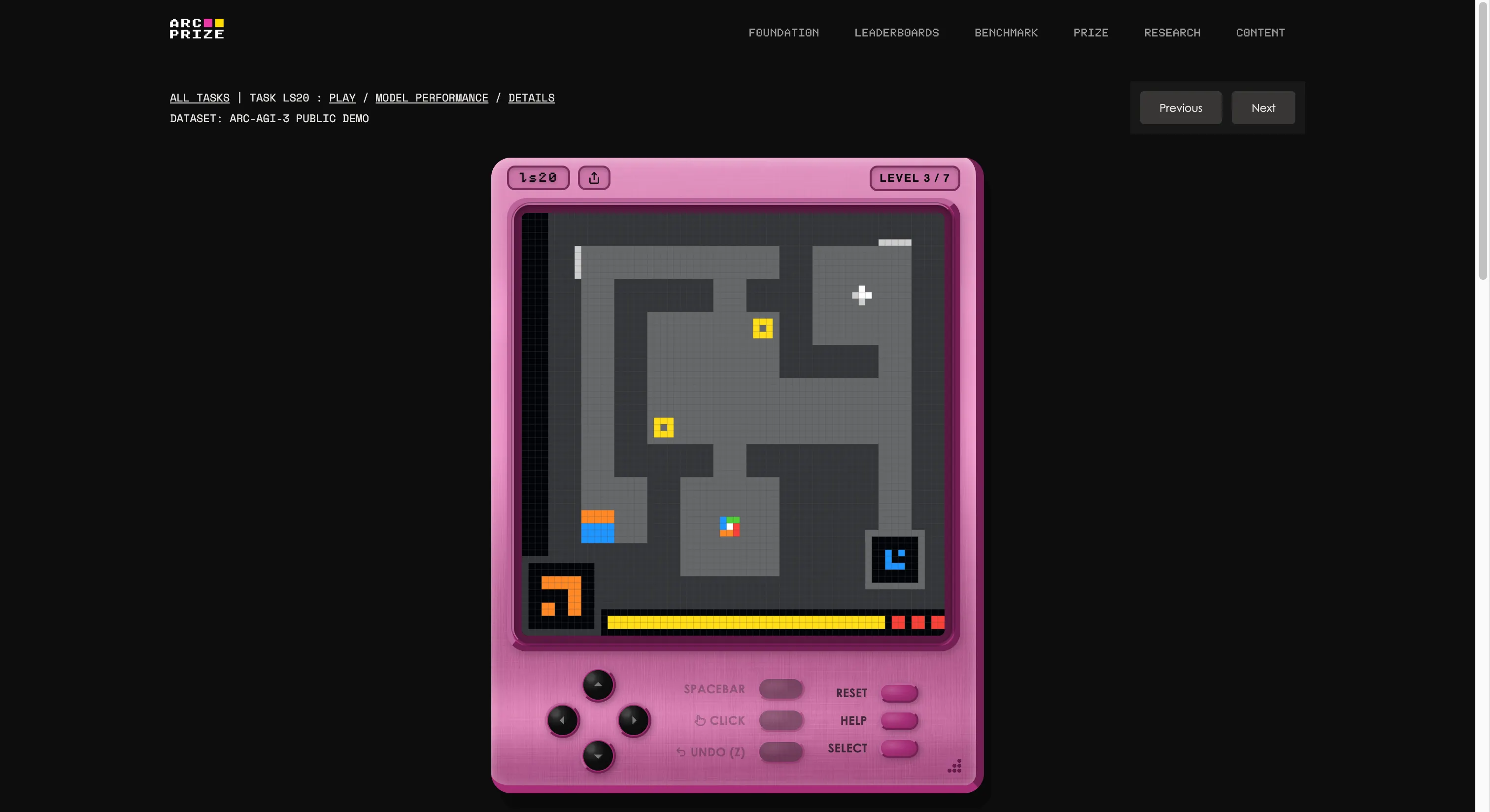
Это также самый яркий пример того, что означает буква «G» в AGI. Когда вы обобщаете, вы можете создавать новые знания (как работает странная игра) без предварительного обучения.
Ранее версии ARC тестировали статические визуальные головоломки — показывать шаблон, предсказывать следующий. Сначала они были сложными. Потом лаборатории добавляли вычислительные мощности и обучение, и бенчмарки практически исчезли. ARC-AGI-1, введенный в 2019 году, тестировал модели на обучении во время выполнения и логике. ARC-AGI-2 продержался около года, пока Gemini 3.1 Pro не достиг 77,1%. Лаборатории очень хорошо насыщают бенчмарки, к которым могут обучаться.
Версия 3 была специально разработана, чтобы этого избежать. 110 из 135 сред остались закрытыми — 55 полузакрыты для API-тестирования и 55 полностью закрыты для соревнований — так что нет набора данных для запоминания. Невозможно перебором пройти через новую игровую логику, которую никогда не видел.
Оценка тоже не делится на «зачет/незачет». ARC-AGI-3 использует так называемый RHAE — относительную эффективность человеческих действий. Базовая точка — это вторая по эффективности, первая — у человека при первом запуске. ИИ, который делает в десять раз больше действий, получает 1% за этот уровень, а не 10%. Формула возводит штраф за неэффективность в квадрат. Блуждание, возврат назад и угадывание получают жесткое наказание.
Лучший ИИ-агент в месячном предварительном тестировании набрал 12,58%. Передовые языковые модели, протестированные через официальный API без пользовательских инструментов, не смогли преодолеть 1%. Обычные люди решили все 135 задач без предварительной подготовки и инструкций. Если это планка, то текущие модели ей не соответствуют.
Есть один важный методологический спор. В отчете ARC говорится, что специально созданный для Duke кастомный инструмент повысил Claude Opus 4.6 с 0,25% до 97,1% на одном варианте среды под названием TR87. Это не означает, что Claude набрал 97,1% по всему ARC-AGI-3; его официальный результат остался 0,25%, но этот сдвиг заслуживает внимания.
Официальный бенчмарк подает агентам JSON-код, а не визуальные изображения. Это либо методологический недостаток, либо демонстрация того, что современные модели лучше обрабатывают понятную человеку информацию, чем сырые структурированные данные. Фонд Шолле признал этот спор, но менять формат не собирается.
«Восприятие содержимого рамки и формат API не являются ограничивающими факторами для производительности передовых моделей на ARC-AGI-3», — говорится в документе. Другими словами, они отвергают идею, что модели не справляются из-за неспособности «видеть» задачи правильно, и считают, что проблема кроется в логике и обобщении.
Реальность AGI была поставлена под сомнение в неделю, когда хайп-машина работала на полную мощность. Помимо комментария Хуанга, Arm назвала свой новый чип для дата-центров «AGI CPU». Сэм Альтман из OpenAI заявил, что они «практически создали AGI», а Microsoft уже продвигает лабораторию, сосредоточенную на создании ASI — следующего этапа после достижения AGI. Термин используют настолько широко, что он начинает означать всё, что удобно с коммерческой точки зрения.
Позиция Шолле проще. Если обычный человек без инструкций может это сделать, а ваша система — нет, значит, у вас нет AGI — есть очень дорогой автодополнятор, которому нужна большая помощь.
ARC Prize 2026 предлагает 2 миллиона долларов в рамках трех конкурсов, все они проходят на Kaggle. Каждый победительский проект должен быть открытым исходным кодом. Время идет, а пока что машины даже близко не подходят к этой цели.
Отказ от ответственности: Информация на этой странице может поступать от третьих лиц и не отражает взгляды или мнения Gate. Содержание, представленное на этой странице, предназначено исключительно для справки и не является финансовой, инвестиционной или юридической консультацией. Gate не гарантирует точность или полноту информации и не несет ответственности за любые убытки, возникшие от использования этой информации. Инвестиции в виртуальные активы несут высокие риски и подвержены значительной ценовой волатильности. Вы можете потерять весь инвестированный капитал. Пожалуйста, полностью понимайте соответствующие риски и принимайте разумные решения, исходя из собственного финансового положения и толерантности к риску. Для получения подробностей, пожалуйста, обратитесь к
Отказу от ответственности.
