OpenAI today (18th) officially released two lightweight new models, GPT-5.4 Mini and GPT-5.4 Nano. The former doubles the speed of the previous generation and is priced at only $0.75 per million input tokens, while the latter offers ultra-low latency and a highly competitive price of $0.20 to target high-throughput markets.
(Background: OpenAI launches GPT-5.2! Aiming to replace professionals, lower hallucinations, and API pricing overview)
(Additional context: Complete overview of OpenAI’s most powerful GPT-5 release event: free access, feature highlights, gpt-5, gpt-5-mini, and gpt-5-nano API prices)
Table of Contents
Toggle
- GPT-5.4 Mini: 2x speed, versatile lightweight main model
- GPT-5.4 Nano: ultra-low latency, designed for high throughput scenarios
- Sub-agent architecture: small models are not downgraded versions but part of system design
OpenAI simultaneously launched GPT-5.4 Mini and GPT-5.4 Nano late tonight (18th). These two models are not flagship-level but are explicitly designed as execution layers within a hybrid AI system: managed by more powerful flagship models, with numerous small models running in parallel behind the scenes to handle daily computations.
OpenAI describes this architecture as “significant improvements in speed and cost-efficiency achieved through partial precision,” reflecting the current AI industry shift from single large models to “multi-agent collaboration.”
GPT-5.4 Mini: 2x speed, versatile lightweight main model
GPT-5.4 Mini is the core product of this release, balancing speed and multitasking capabilities. Compared to its predecessor, it doubles inference speed and has been upgraded across key functions such as code generation, multimodal understanding, and tool calling.
In benchmark tests, GPT-5.4 Mini achieved 54.4% on SWE-Bench Pro (automatic GitHub issue repair) and 72.1% on OSWorld-Verified (desktop automation), both leading figures among models in its class.
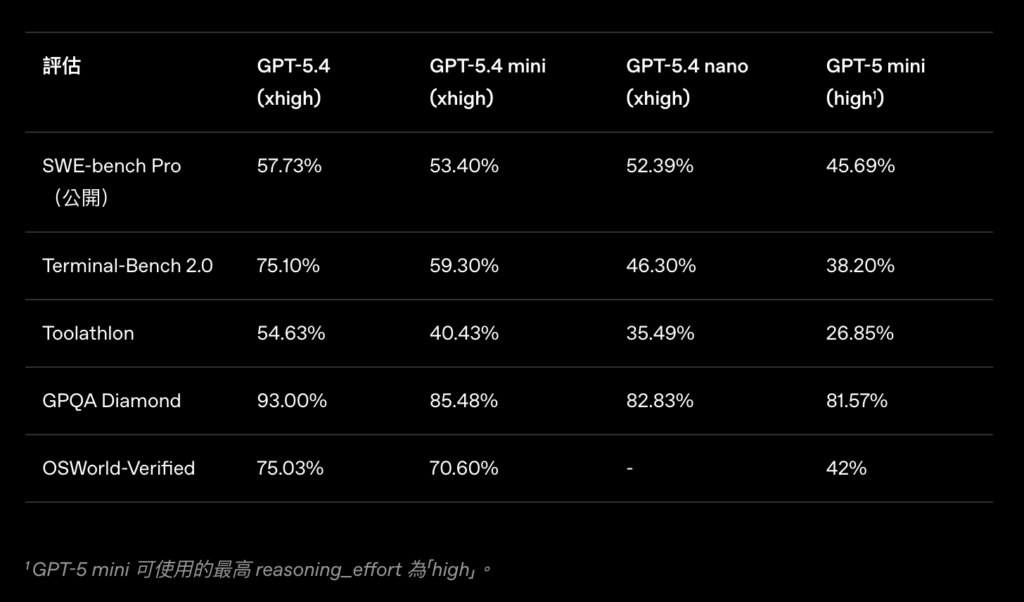
Functionally, it supports mixed text and image input, tool calling, internet and file search, and UI interaction for computer operations, covering nearly all modern AI application needs. OpenAI lists primary use cases including: code assistants, IDE integration, code review, screenshot interpretation, desktop sub-agents, and real-time interactive systems.
Pricing-wise, GPT-5.4 Mini costs $0.75 per million tokens for input and $4.50 for output, continuing OpenAI’s recent strategy of aggressively lowering costs.
Availability is immediate: GPT-5.4 Mini is fully accessible via ChatGPT (free and Go subscription tiers), Codex, and OpenAI API, and can also be deployed through Azure AI Foundry.
GPT-5.4 Nano: ultra-low latency, designed for high throughput scenarios
GPT-5.4 Nano is positioned more clearly: OpenAI calls it “the smallest and most cost-effective model currently,” tailored for scenarios requiring extremely low latency and massive parallel processing.
Benchmark results show SWE-Bench Pro score at 52.4% and OSWorld at 39.0%. Slightly below Mini, but given its ultra-low price, its value-for-money is impressive.
Functionally, Nano supports instruction following, function calling, basic coding, image understanding, classification, and data extraction, suitable for most structured tasks but not supporting complex desktop operations or deep reasoning.
Pricing is $0.20 per million tokens for input and $1.25 for output, roughly a quarter of Mini’s price, ideal for enterprises needing large-scale automation calls. Use cases include classification and data extraction, code sub-agents, high-volume automation, request routing, form processing, and customer service workflows.
Note that GPT-5.4 Nano is currently only available via API and will not appear in the ChatGPT user interface, clearly targeting developers and enterprise products.
Sub-agent architecture: small models are not downgraded versions but part of system design
OpenAI’s promotional phrase for these models is “born for the era of sub-agents,” which reflects specific product logic.
In multi-agent AI systems, flagship models (like GPT-5 or o-series inference models) handle high-level planning and complex judgment, while numerous repetitive, structured sub-tasks—web scraping, data transformation, form filling, code snippet generation—are handled by smaller, faster, cheaper models running in parallel. GPT-5.4 Mini and Nano are designed for this execution layer.
This approach also explains why both models emphasize tool calling and computer operation capabilities: as automation in AI applications increases, small models that can reliably execute commands and interact with external systems are just as valuable as larger flagship models.

Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.
