Google випустила значне оновлення Gemini 3 Deep Think, яке у тесті ARC-AGI-2 показало результат 84,6%, суттєво перевищивши Claude Opus 4.6 (68,8%) та GPT-5.2 (52,9%), одночасно досягнувши рівня «легендарного майстра» у Codeforces.
(Попередній огляд: З’явилася модель ChatGPT для навчання: західний закат або нова ера освіти?)
(Додатковий контекст: Google офіційно презентувала «Gemini 3»! Що робить цю модель найрозумнішою у світі?)
Зміст статті
- Не лише тестування, а й виявлення людських помилок
- Зміни у ринкових долях
- Вплив на криптоіндустрію
- Науковий етап перемоги тільки починається
13-го числа Google оголосила про значне оновлення Gemini 3 Deep Think. У тесті ARC-AGI-2, спеціально розробленому для перевірки здатності моделей логічно мислити без заздалегідь заданих правил, Gemini 3 Deep Think набрав 84,6%.
Для порівняння, Claude Opus 4.6 (у режимі Thinking Max) отримав 68,8%, GPT-5.2 (у режимі Thinking xhigh) — 52,9%, а середня оцінка людських тестувальників становить близько 60%.
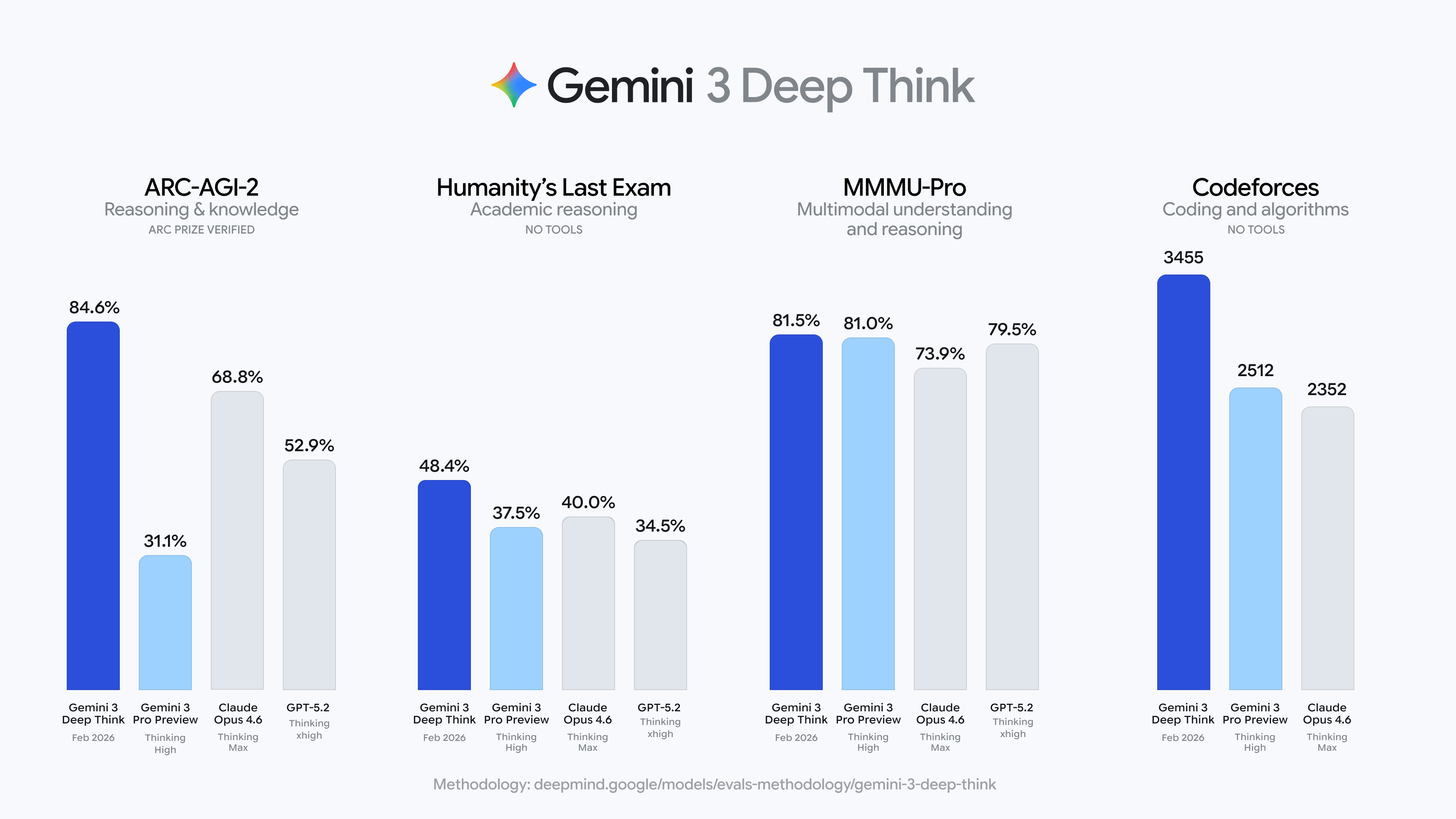
Ще більш вражаюче, що на базовій версії ARC-AGI-1 Deep Think показав результат 96%, фактично досягши межі тесту, який раніше вважався одним із найскладніших для штучного інтелекту.
Зараз Deep Think доступний підписникам Google AI Ultra, а API — для раннього доступу підприємствам.
Не лише тестування, а й виявлення людських помилок
Крім результатів, у повідомленні Google згадано один цікавий випадок: Deep Think під час рецензування математичної статті, що пройшла незалежне рецензування, виявив логічну помилку, яку раніше не помітили всі рецензенти. Статтю підтвердили математики з Університету Рутгерса.
Цей випадок важливий тим, що він демонструє здатність моделі працювати не лише у стандартних тестах, а й у реальних наукових сценаріях. Рецензування — це ключовий механізм контролю якості в науці, і якщо AI може стабільно допомагати у цьому процесі, це суттєво прискорить наукові дослідження, перевищуючи будь-які результати тестів.
Deep Think також досягнув рівня золотої медалі на Міжнародній фізичній олімпіаді 2025 року та Міжнародній хімічній олімпіаді, а у рейтингу Elo на Codeforces має 3455 балів, що відповідає рівню «легендарного майстра», і лише кілька людських програмістів у світі досягають такого рівня.
Ще один рекорд — у «останньому іспиті людства» (Humanity’s Last Exam), створеному експертами з різних галузей, щоб ускладнити завдання для AI, Deep Think отримав 48,4% без використання інструментів.
Зміни у ринкових долях
Конкуренція між трьома гігантами AI змінює розподіл ринку. Частка ChatGPT з пікових 87% знизилася до приблизно 68%, тоді як Gemini стрімко зросла з менш ніж 5% до понад 18%, а Claude від Anthropic поступово захоплює корпоративний сегмент.
Унікальна перевага Google — це можливість поширення. Gemini інтегрована у Android, Chrome, Google Workspace та пошукову систему, що дозволяє навіть при рівності можливостей з конкурентами залучати користувачів через канали.
Однак перевага у поширенні — двосічний меч. Якщо досвід користування Gemini буде незадовільним, вона може швидше за будь-який інший продукт втратити довіру користувачів, оскільки вони «пасивно контактують», а не «свідомо обирають». Користувачі OpenAI платять за послуги, тому мають вищу толерантність і лояльність.
Вплив на криптоіндустрію
Кожне оновлення у гонці озброєнь AI підвищує попит на обчислювальні ресурси. Вартість навчання передових моделей зросла з сотень мільйонів доларів у 2024 році до кількох мільярдів у 2026-му. Це безпосередньо впливає на два напрямки.
Перший — трансформація майнерів біткоїна. Коли прибутковість майнінгу знижується (згідно з оцінками JPMorgan, вартість виробництва BTC знизилася до 77 тисяч доларів, тоді як ціна коливається біля 66 тисяч), майнери з великими обчислювальними потужностями швидко переключаються на AI-обчислювальні послуги.
Замість «виходу з ринку» вони «перекваліфікуються», перетворюючись із майнерів біткоїна на постачальників AI-обчислень за контрактами.
Другий — нарратив навколо AI-токенів. Коли Google, OpenAI або Anthropic випускають значущі оновлення, на блокчейні з’являються короткострокові спекуляції навколо AI-активів (децентралізованих протоколів обчислень).
Однак фундаментальні проблеми цих токенів залишаються: децентралізовані обчислення ще далекі від потреб корпоративного рівня для тренування AI. Нарратив може швидко розвиватися, але інфраструктура — ні.
Науковий етап перемоги тільки починається
Оновлення Deep Think повернуло Google у лідери AI-гонки, принаймні у сфері логіки та науки. Але якщо уважно прочитати заяву Google, помітно тонкий зсув у позиціонуванні: тепер вони не акцентують увагу на «найрозумнішому універсальному AI», а знову і знову підкреслюють «створений для науки».
Коли стандарти універсального AI стають все більш насиченими та важко відрізнити один від одного, цінність «мій AI допомагає у наукових дослідженнях» стає переконливішою за «мій AI має найвищі бали у тестах». Якщо Deep Think зможе стабільно підтримувати рецензентів, прискорювати відкриття ліків або знаходити людські прогалини у фізичних моделях, це матиме значення більше за будь-який рейтинг.
Проблема у тому, що перехід від «може набрати високий бал у тесті» до «може надійно допомагати у реальній науці» може бути більш віддаленим, ніж натякає Google, адже тестові завдання мають стандартні відповіді, а наука — ні.

Застереження: Інформація на цій сторінці може походити від третіх осіб і не відображає погляди або думки Gate. Вміст, що відображається на цій сторінці, є лише довідковим і не є фінансовою, інвестиційною або юридичною порадою. Gate не гарантує точність або повноту інформації і не несе відповідальності за будь-які збитки, що виникли в результаті використання цієї інформації. Інвестиції у віртуальні активи пов'язані з високим ризиком і піддаються значній ціновій волатильності. Ви можете втратити весь вкладений капітал. Будь ласка, повністю усвідомлюйте відповідні ризики та приймайте обережні рішення, виходячи з вашого фінансового становища та толерантності до ризику. Для отримання детальної інформації, будь ласка, зверніться до
Застереження.
Пов'язані статті
黃仁勳 назвав OpenClaw «найважливішим випуском програмного забезпечення за всю історію», за три тижні кількість завантажень перевищила 30 років накопичення Linux
Генеральний директор Nvidia 黄仁勋 на конференції похвалив відкритий вихідний код AI-програмного забезпечення OpenClaw, вважаючи, що це може бути важливим релізом програмного забезпечення, кількість завантажень встановила рекорд. Він підсумував, що розвиток AI пройшов через три переломні моменти, зазначив, що зростання потреб у обчислювальній потужності безпосередньо пов’язане з доходами, і в майбутньому країни не повинні відмовлятися від інтелекту.
GateNews10хв. тому
Ціни на нафту за цей тиждень зросли майже на 20%, азійські фондові ринки зафіксували найбільше за шість років щотижневе падіння
Ціни на нафту незначно знизилися, що принесло невелике полегшення світовим фондовим ринкам, але конфлікт у Близькому Сході не зменшується, азійські фондові ринки зафіксували найбільше за шість років щотижневе падіння. США можуть втрутитися у ф'ючерсний ринок, ціни на нафту все ще зросли майже на 20%. Ринкам бракує достатньої інформації для оцінки екстремальних сценаріїв.
GateNews26хв. тому
10x Research: Інституційний капітал переосмислює ринок криптовалютних акцій, структурні зміни в секторі майнингових компаній
10x Research звіт показує, що рух капіталу інституцій та коригування активів компаній переосмислюють структуру ринку криптовалютних акцій: частина криптоакцій зростає, частина маргіналізується. Ціна акцій Bitdeer Technologies нещодавно коливалась через коригування структури капіталу та очищення резервів біткойнів, що сприяє трансформації у високопродуктивні обчислення та інфраструктуру AI. У цілому на ринку ціни Circle та деяких CEX значно відновилися.
GateNews28хв. тому
21Shares Polkadot фізичний ETF незабаром запуститься на NASDAQ
Gate News повідомляє, 6 березня 21Shares US оголосила, що її спотовий ETF на Polkadot — 21Shares Polkadot ETF — незабаром запуститься на NASDAQ.
GateNews41хв. тому
21Shares Polkadot спотовий ETF сьогодні запущено на NASDAQ, біржовий код TDOT
Gate News повідомляє, що 6 березня 21Shares US оголосила про запуск свого фізичного ETF на Polkadot — 21Shares Polkadot ETF (код акції: TDOT) — сьогодні (за місцевим часом 6 березня) на NASDAQ.
GateNews41хв. тому
Аналізатор Bloomberg: ETF на Solana залучив усього 1,5 мільярда доларів США, приблизно 50% з них належать інституціям з управління понад 1 мільярд доларів США
Ерік Бальчунус зазначив, що з моменту запуску спотового ETF у липні SOL знизився на 57%, але все ще залучив 1,5 мільярда доларів інвестиційних коштів, що свідчить про серйозність інвесторської бази та оптимізм щодо майбутніх перспектив.
GateNews51хв. тому

