Ferramenta de IA CanIRun.ai consegue detectar automaticamente as especificações do hardware do utilizador através do navegador, estimando quais modelos de LLM podem ser executados e a velocidade de inferência. Interessados podem experimentar para entender melhor.
(Resumindo: Clawdbot é uma ferramenta que faz o Mac mini vender-se rapidamente 24/7 como um mordomo de IA)
(Complemento: Não siga cegamente o OpenClaw, o AI do caranguejo é forte, mas pode não ser adequado para si)
Índice do artigo
Toggle
- Pequenas desvantagens do Canirun.ai
- Alternativa de linha de comando: surge o llmfit
- O que a comunidade mais deseja
Quer instalar um grande modelo de linguagem (LLM) localmente? A dúvida mais comum para iniciantes é: Qual o modelo que o meu computador consegue rodar? Este artigo apresenta uma ferramenta que tem gerado discussão na comunidade Hacker News: o CanIRun.ai.
O CanIRun.ai é uma ferramenta web simples: basta abrir o navegador e ela detecta automaticamente o modelo da sua GPU e a memória disponível usando a API WebGPU. Com base na quantidade de parâmetros, nível de quantização (Q4_K_M, Q8_0, F16, etc.) e largura de banda da memória, ela estima a viabilidade de execução e a velocidade de inferência (tokens/s), apresentando os resultados com uma classificação de S a F.
A abrangência vai desde modelos super leves com 0,8B de parâmetros até modelos gigantes de 1T de parâmetros (MoE - Mixture of Experts), com fontes de dados incluindo llama.cpp, Ollama e LM Studio, entre outros.
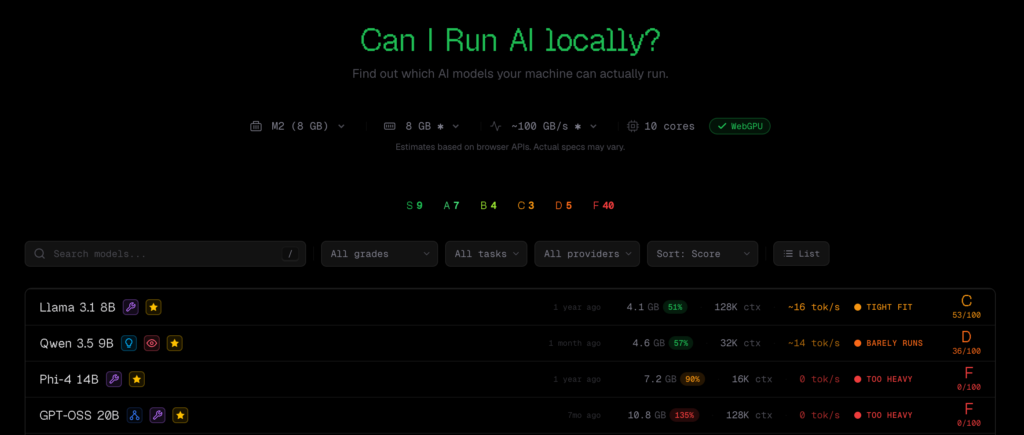
Pequenas desvantagens do Canirun.ai
Embora a ideia da ferramenta seja bem recebida, há críticas. As principais focam em duas áreas: cobertura de hardware incompleta e discrepâncias entre estimativa e testes reais.
A falta de listagem de certos hardwares é frequentemente mencionada: RTX Pro 6000, RTX 5060 Ti 16GB, GPUs de laptops de várias marcas não aparecem na lista. Quanto aos chips Apple, embora estejam listados, o limite máximo é de 192GB de memória, enquanto o M3 Ultra suporta até 512GB.
Sobre a precisão das estimativas, alguns usuários relataram que os testes reais não condizem com o que o CanIRun.ai indica. Casos de “consegue rodar, mas o site diz que não” aparecem frequentemente, levando alguns a ignorar os resultados.
Apesar de melhorias possíveis, para iniciantes, o CanIRun.ai ainda é uma ferramenta rápida para verificar o hardware.
Alternativa de linha de comando: surge o llmfit
Na comunidade, há quem recomende o llmfit: uma ferramenta de linha de comando que acessa diretamente ferramentas do sistema (como nvidia-smi) para obter informações precisas da GPU, sem depender da API do navegador. Muitos consideram que é mais útil e preciso do que a versão web.
Por outro lado, o llmfit também levanta uma questão: alguns usuários ficaram surpresos por ela identificar com precisão o modelo da GPU sem solicitar permissões explícitas. Isso tocou na sensível questão de privacidade e fingerprinting do navegador: se uma ferramenta web consegue detectar sua placa de vídeo via WebGPU, como esses dados podem ser usados?
Alguns sugerem que essa funcionalidade idealmente deveria estar integrada ao Ollama, permitindo que o usuário, via linha de comando, selecione automaticamente os modelos compatíveis com seu hardware, eliminando a necessidade de pesquisa manual.
O que a comunidade mais deseja
Com base no feedback, o principal limite do CanIRun.ai não é só a precisão da estimativa, mas a sua avaliação ser muito limitada. Os usuários querem saber: qual o melhor modelo, em termos de qualidade e velocidade, que meu hardware consegue rodar? Atualmente, a ferramenta só responde se é possível ou não rodar, mas não se a performance é satisfatória.
A comunidade deseja que futuramente seja incluída uma pontuação de capacidade do modelo, combinada com a estimativa de hardware, para oferecer uma escolha mais completa. Outras melhorias técnicas incluem: incorporar estratégias de compartilhamento de memória CPU (para GPUs com pouca memória, usar memória do sistema), suporte a técnicas de descarregamento de cache KV, e correções na lógica de cálculo de modelos MoE.
No geral, a direção da ferramenta é correta e há demanda de mercado: a barreira para usar IA local ainda é alta para o usuário comum. Uma ferramenta que rapidamente avalie “o que meu computador consegue rodar” é uma necessidade real. O CanIRun.ai tocou nesse ponto, mas ainda precisa de refinamento.
Isenção de responsabilidade: As informações contidas nesta página podem ser provenientes de terceiros e não representam os pontos de vista ou opiniões da Gate. O conteúdo apresentado nesta página é apenas para referência e não constitui qualquer aconselhamento financeiro, de investimento ou jurídico. A Gate não garante a exatidão ou o carácter exaustivo das informações e não poderá ser responsabilizada por quaisquer perdas resultantes da utilização destas informações. Os investimentos em ativos virtuais implicam riscos elevados e estão sujeitos a uma volatilidade de preços significativa. Pode perder todo o seu capital investido. Compreenda plenamente os riscos relevantes e tome decisões prudentes com base na sua própria situação financeira e tolerância ao risco. Para mais informações, consulte a
Isenção de responsabilidade.
