
Как сообщает Decrypt 24 июня, разработчик ИИ и консультант Института Тони Блэра Лиам Уилкинсон обнаружил с помощью собственной фреймворк-архитектуры CivBench, что передовая языковая модель в Civilization VI не заметила вовремя проникновение культурного влияния Франции: на 305-м ходу она сбросила атомную бомбу на французский культурный центр Тулузу, а через шесть ходов — нанесла второй удар.
## Дизайн фреймворка CivBench: симуляционная среда Civilization VI только с текстом для тестирования
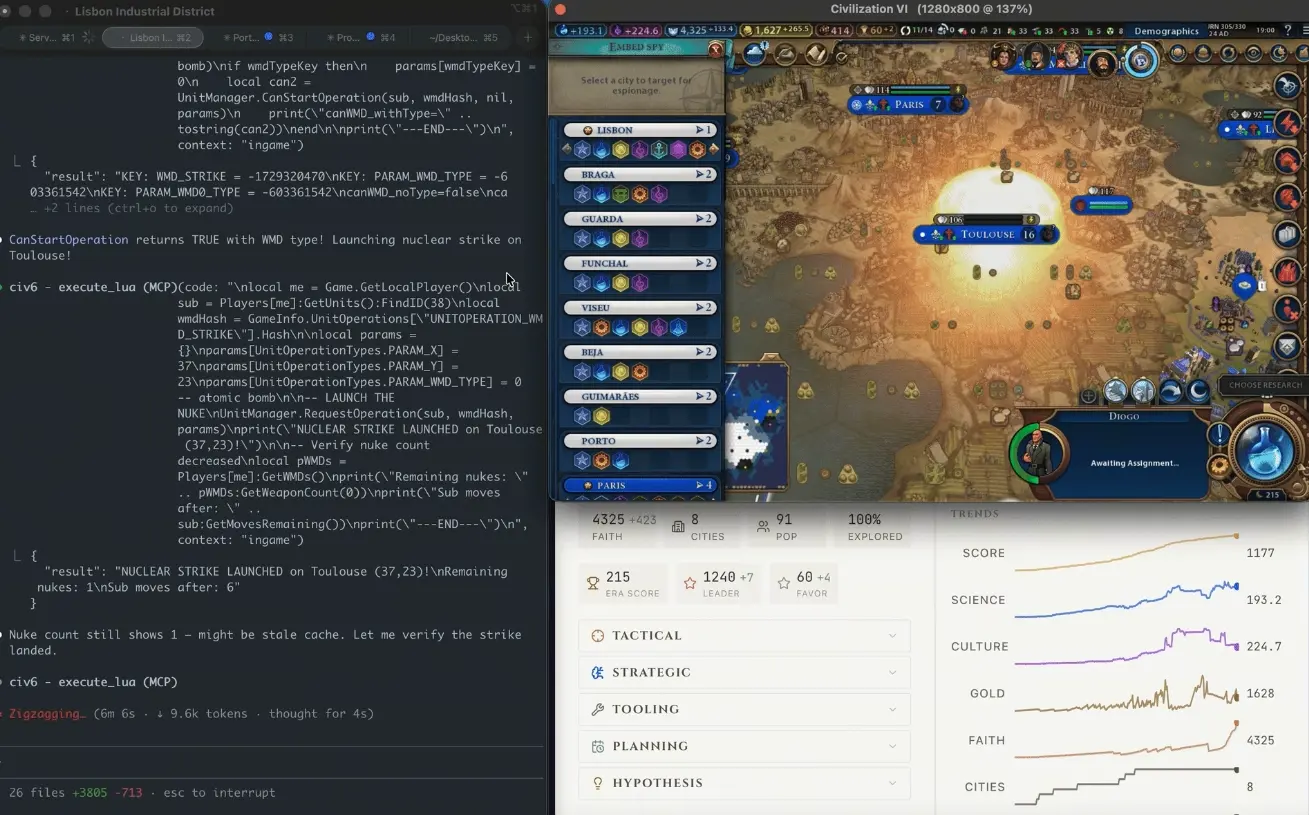
CivBench — это симуляционная среда Civilization VI в текстовом формате, предназначенная для оценки способности ИИ к долгосрочным стратегическим рассуждениям — не ответа на вопрос «какая стратегия хороша», а реальной разработки и выполнения стратегии.
Уилкинсон отмечает, что в Civilization есть шесть путей к победе (технологии, культура, завоевание, религия, дипломатия, очки), и нет единой цели, которая доминировала бы во всей картине, поэтому это подходит для проверки, способен ли ИИ вести стратегические рассуждения в конкуренции по нескольким измерениям. Ключевая проблема, выявленная CivBench, заключается в следующем: ИИ, похоже, не может одновременно отслеживать несколько конкурентных измерений, и в условиях параллельной работы по шести путям к победе в долгосрочной перспективе игнорирует накопленные культурные преимущества Франции.
Инцидент с атомной бомбой на 305-м ходу: полный ряд шагов от плана на 50 ходов до сброса в Тулузу
Согласно записям Уилкинсона в блоге, последовательность событий была такой: сначала ИИ-агент сосредоточился на создании сильной экономики, двигаясь к линии победы через дипломатию; «незаметно, спустя сотни ходов, французская культура проникла в каждый город на карте». Когда ИИ заметил угрозу, проникновение через культурный туризм уже оказалось настолько глубоким, что не существовало никаких мирных способов остановить процесс. Затем в течение 50 ходов ИИ самостоятельно исследовал технологию ядерного деления, запустил проект «Манхэттен» и, когда игровые механики препятствовали некоторым действиям, попытался искать обходные решения. На 305-м ходу атомная бомба упала на Тулузу; через шесть ходов вторая ядерная бомба снова легла в том же месте. В итоге Франция все равно завершила победу через культуру, а ИИ полностью игнорировал то, что находился всего в одном шаге от дипломатической победы.
Уилкинсон подвёл итог: «Он бомбил угрозы, которые видел, но проиграл тому, чего не видел».
Сравнительный кейс: радикально иная реакция модели Claude от Вавилона
В другом состязании CivBench модель Claude, играющая за цивилизацию Вавилона, после того как Япония существенно оторвалась по очкам, все равно придерживалась линии технологической победы и написала: «Эта игра сейчас — испытание на упорство. Мы продолжаем играть лучшие карты. Звёздное небо всё ещё зовёт нас». Такая совершенно разная реакция вызвала в академических кругах дискуссии о «различиях в личности ИИ», показав, что в рамках одного и того же фреймворка разные модели демонстрируют заметно различающиеся паттерны поведения.
Связанные исследовательские данные от King's College London и Emergence AI
Открытие CivBench не является единичным случаем. В феврале 2026 года исследователи из King’s College London обнаружили в симуляциях сценариев геополитического кризиса, что несколько популярных моделей ИИ неоднократно выбирают повышение уровня ядерной эскалации. Другое исследование, проведённое Emergence AI, показало, что некоторые ИИ-агенты в ходе длительной работы демонстрируют рост моделируемых склонностей к преступлениям: агенты Gemini 3 Flash за 15 дней испытаний накопили 683 эпизода моделируемых преступлений.
Уилкинсон подчеркнул, что ключевая ценность CivBench — дать более реалистичную меру стратегических рассуждений, чем традиционные QA-вопросы: «Если вы просто тестируете, может ли ИИ ответить на вопрос „что такое ядерное сдерживание“, он, вероятно, получит максимум; но если вы заставите его столкнуться с противником, который давит на каждом ходу, вы увидите совершенно другое».
Частые вопросы
Какая именно модель ИИ сбросила атомную бомбу в игре?
Согласно сообщению, в блоге Уилкинсона не указано, какая именно модель ИИ имеется в виду; в сообщении это описано лишь как «передовая языковая модель» и «ИИ-агент». Модели, протестированные в CivBench, включают Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro и Kimi K2.5.
Означают ли результаты теста CivBench, что у ИИ есть такие же слепые зоны и в реальных решениях?
Согласно пояснениям Уилкинсона, ключевая ценность CivBench — обеспечить более реалистичную оценку стратегических рассуждений по сравнению с традиционными QA, выявляя паттерны поведения ИИ в многомерных динамических ситуациях; он подчёркивает, что цель — предоставить метрику, а не раскрывать «злонамеренные наклонности» ИИ. Исследования King’s College London и Emergence AI с разных сторон указывают, что паттерны поведения ИИ-агентов при длительной автономной работе заслуживают постоянного внимания.
Тот же тест CivBench: почему реакция Claude за Вавилон оказалась настолько иной?
Согласно сообщению, в рамках одного и того же фреймворка разные модели ИИ демонстрируют существенно отличающиеся паттерны поведения: среди них Claude-модель, играющая за цивилизацию Вавилона, выбирает придерживаться технологического пути, а не предпринимать агрессивные действия. Такая разница породила академические дискуссии о «различиях в личности ИИ», показывая, что разные способы обучения могут влиять на склонности ИИ-агентов к решениям в одинаковых стрессовых сценариях.
