Коротко
- Microsoft випустила два різні режими, які поєднують GPT і Claude, щоб підвищити якість AI-досліджень.
- Critique змушує моделі співпрацювати, тоді як Council змушує їх працювати паралельно, а третій суддя знаходить розбіжності.
- Цей двомодельний робочий процес усуває галюцинації, слабкі посилання та інші проблеми, пов’язані з AI-дослідженнями на основі однієї моделі.
AI глибоких досліджень цього року став однією з найгарячіших гонок озброєнь у сфері технологій. Google оголосила свого дослідницького агента для Gemini в грудні 2024 року, OpenAI випустила власний дослідницький агент у лютому 2025 року, xAI пішла за нею, Perplexity зробила ставку на продовження, а Claude від Anthropic здобув лояльну аудиторію серед професіоналів, яким потрібні детальні, підкріплені посиланнями відповіді, представивши свого агента в квітні минулого року.
Усі компанії намагаються переконати вас, що їхня єдина AI-модель — найрозумніший дослідник у кімнаті. Microsoft щойно сказала: Навіщо обирати один?
Компанія в понеділок анонсувала дві нові функції для інструмента M365 Copilot’s Researcher — під назвами Critique і Council — які ставлять GPT від OpenAI та Claude від Anthropic працювати над тією самою дослідницькою задачею послідовно. Результат, згідно з тестуванням Microsoft проти галузевого бенчмарка, набирає більше балів, ніж будь-яка система, включена в цей тест, зокрема моделі від провідних AI-компаній.
Представляємо Critique — нову багатомодельну систему глибоких досліджень у M365 Copilot.
Ви можете використовувати кілька моделей разом, щоб генерувати оптимальні відповіді та звіти. pic.twitter.com/m4RlQmCKzs
— Сатья Наделла (@satyanadella) 30 березня 2026
“Critique — це нова багатомодельна система глибоких досліджень, створена для складних дослідницьких задач. Вона відокремлює генерацію від оцінювання та використовує комбінацію моделей із Frontier labs, зокрема Anthropic і OpenAI”, — пояснює Microsoft. “Одна модель керує фазою генерації: планує задачу, ітеративно проходить через пошук і створює початковий чернетковий варіант, тоді як друга модель фокусується на перевірці та доопрацюванні, діючи як експертний рецензент ще до того, як буде згенеровано фінальний звіт.”
Ось базова проблема, яку Critique покликана виправити: Усі інструменти для AI-досліджень сьогодні працюють однаково. Ви ставите запитання, одна модель планує пошук, прочісує джерела, пише звіт і повертає його вам. Одна-єдина модель робить усе без жодної перевірки її роботи.
У результаті можуть прослизнути деякі галюцинації, виникнути помилки в посиланнях, з’явитися фейкові або неточні твердження тощо.
Critique ламає цей робочий процес у дві частини. GPT обробляє першу фазу — він планує дослідження, витягує джерела й пише початковий чернетковий варіант. Потім Claude вступає як суворий редактор: він перевіряє звіт на фактичну точність, якість посилань і те, чи відповідь справді охопила те, про що просили. Лише після цієї перевірки фінальний звіт доходить до користувача. Microsoft каже, що ролі з часом можуть працювати й у протилежному напрямку: Claude може складати чернетку, а GPT — рецензувати, але наразі GPT іде першим.
На бенчмарку DRACO — стандартизованому тесті, який охоплює 100 складних дослідницьких задач у 10 доменах, включно з медициною, правом і технологіями, — Copilot із Critique набрав 57.4. очок, тоді як Claude Opus від Anthropic сам по собі набрав 42.7. Комбінована система Microsoft перевершує наступний найкращий результат майже на 14%.
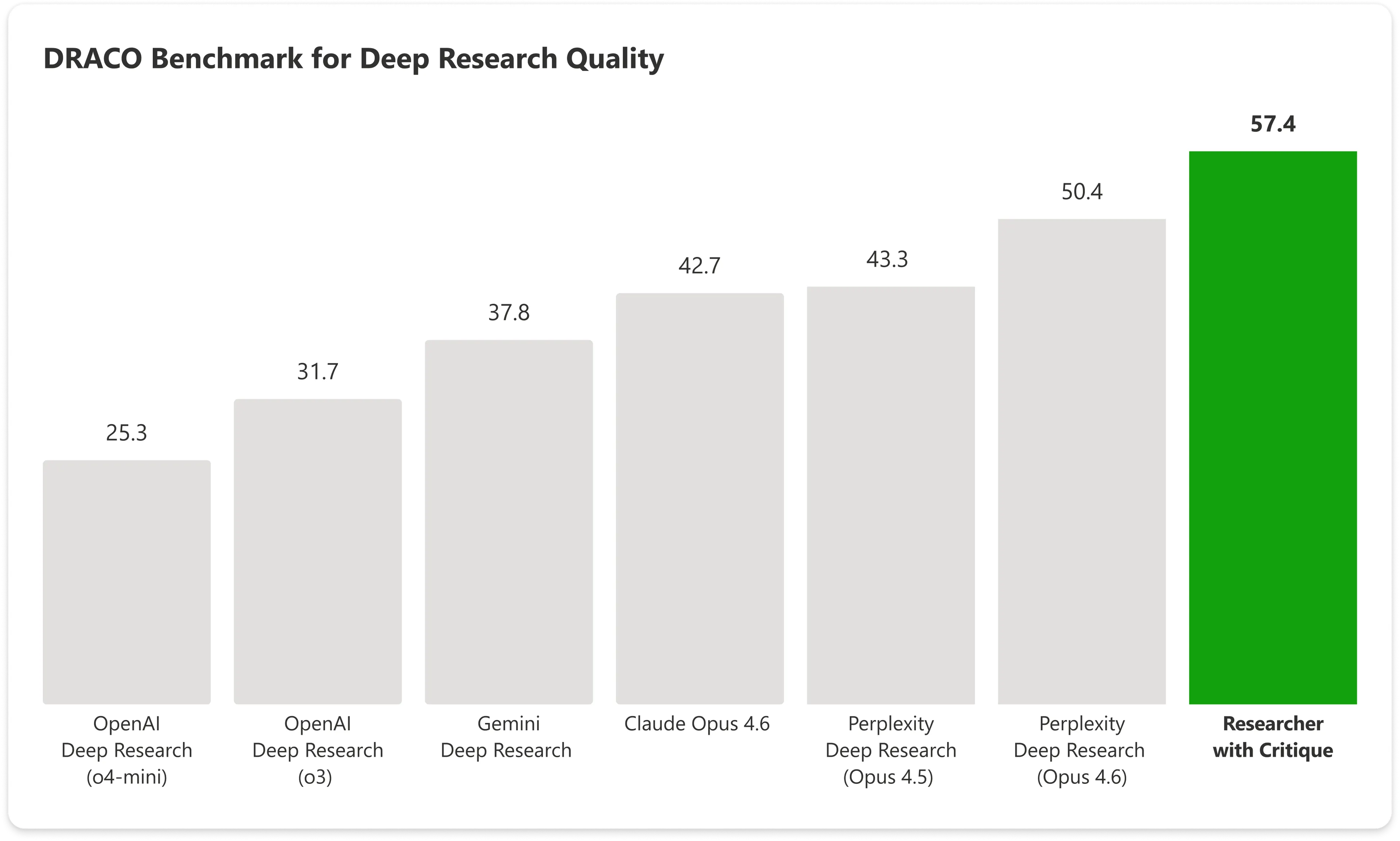
Зображення: Microsoft
Найбільші прирости проявилися в ширині аналізу та якості подачі, а також зафіксували значне покращення фактичної точності.
Друга функція, Council, застосовує інший підхід до тієї самої проблеми. Замість того, щоб одна модель перевіряла роботу іншої, Council запускає GPT і Claude одночасно та ставить їхні повні звіти поруч. Потім третя “модель-суддя” читає обидва результати й пише підсумок, пояснюючи, де дві AI домовилися, де вони розійшлися, і які унікальні ракурси кожна з них помітила, але яких інша не врахувала. Порівнювати інструменти для AI-досліджень вручну користувачам доводилося робити самим — аж до тепер.
У Critique моделі по суті співпрацюють одна з одною, тоді як у Council моделі конкурують одна з одною.
У Researcher Critique є типовим режимом, тоді як Council вимагає від вас вибрати “Model Council” у перемикачі, щоб увімкнути режим “поруч”. Обидві функції наразі доступні користувачам, які підключені до програми Microsoft Frontier — каналу раннього доступу для найновіших можливостей Copilot. Ліцензія на Microsoft 365 Copilot (30 доларів/користувач/місяць) потрібна, але користувачі також мають бути зареєстровані у Frontier, щоб отримати доступ до них.
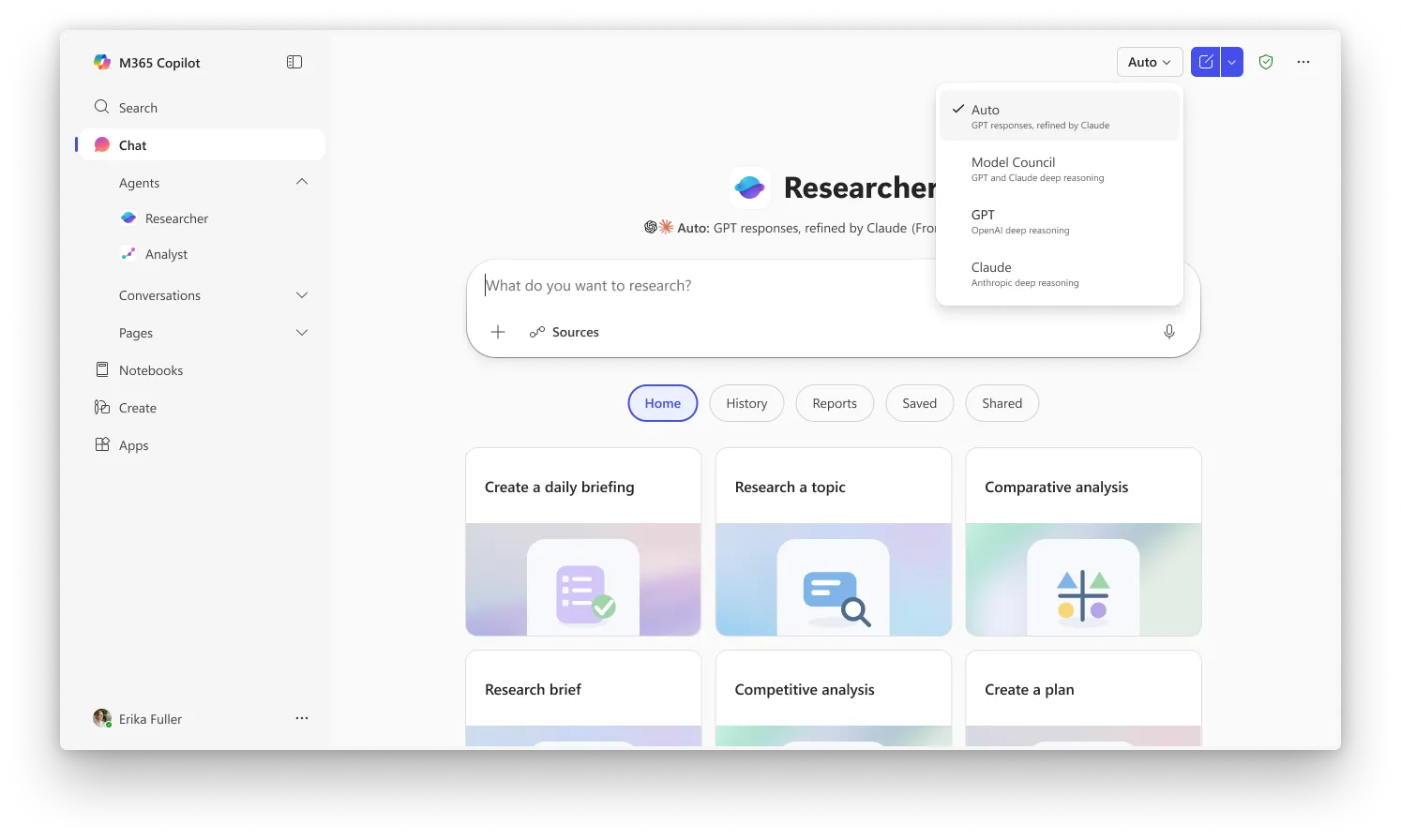
Зображення: Microsoft
OpenAI і Microsoft мають партнерство на мільярди доларів, але ставка Microsoft полягає в тому, що жодна одна модель не втримується на вершині надовго, і що справжня цінність — в оркестраційному шарі, який направляє задачі до тієї комбінації, що працює найкраще.
Застереження: Інформація на цій сторінці може походити від третіх осіб і не відображає погляди або думки Gate. Вміст, що відображається на цій сторінці, є лише довідковим і не є фінансовою, інвестиційною або юридичною порадою. Gate не гарантує точність або повноту інформації і не несе відповідальності за будь-які збитки, що виникли в результаті використання цієї інформації. Інвестиції у віртуальні активи пов'язані з високим ризиком і піддаються значній ціновій волатильності. Ви можете втратити весь вкладений капітал. Будь ласка, повністю усвідомлюйте відповідні ризики та приймайте обережні рішення, виходячи з вашого фінансового становища та толерантності до ризику. Для отримання детальної інформації, будь ласка, зверніться до
Застереження.

