ブロックセック:AIはスマートコントラクト監査で人間に取って代わることはできない
TapChiBitcoin
ブロックセック(BlockSec)のセキュリティ企業は、OpenAIとParadigmが開発したAIによるスマートコントラクト監査評価基準「EVMBench」の再検証を行いました。結果は、実際の攻撃シナリオに直面した際にAIボットの効果が著しく低下することを示しています。
研究チームは、より多くのモデル構成を含む試験環境を拡張し、最近発生した新たなセキュリティインシデントも追加しました。これらのデータは、AIモデルの訓練データには一切含まれていません。
AIはまだセキュリティ専門家の代替にはなり得ませんが、報告書は、機械知能が人間のコード検査を自然に補完する役割を果たす可能性を強調しています。
初期のEVMBench結果は楽観的すぎる可能性
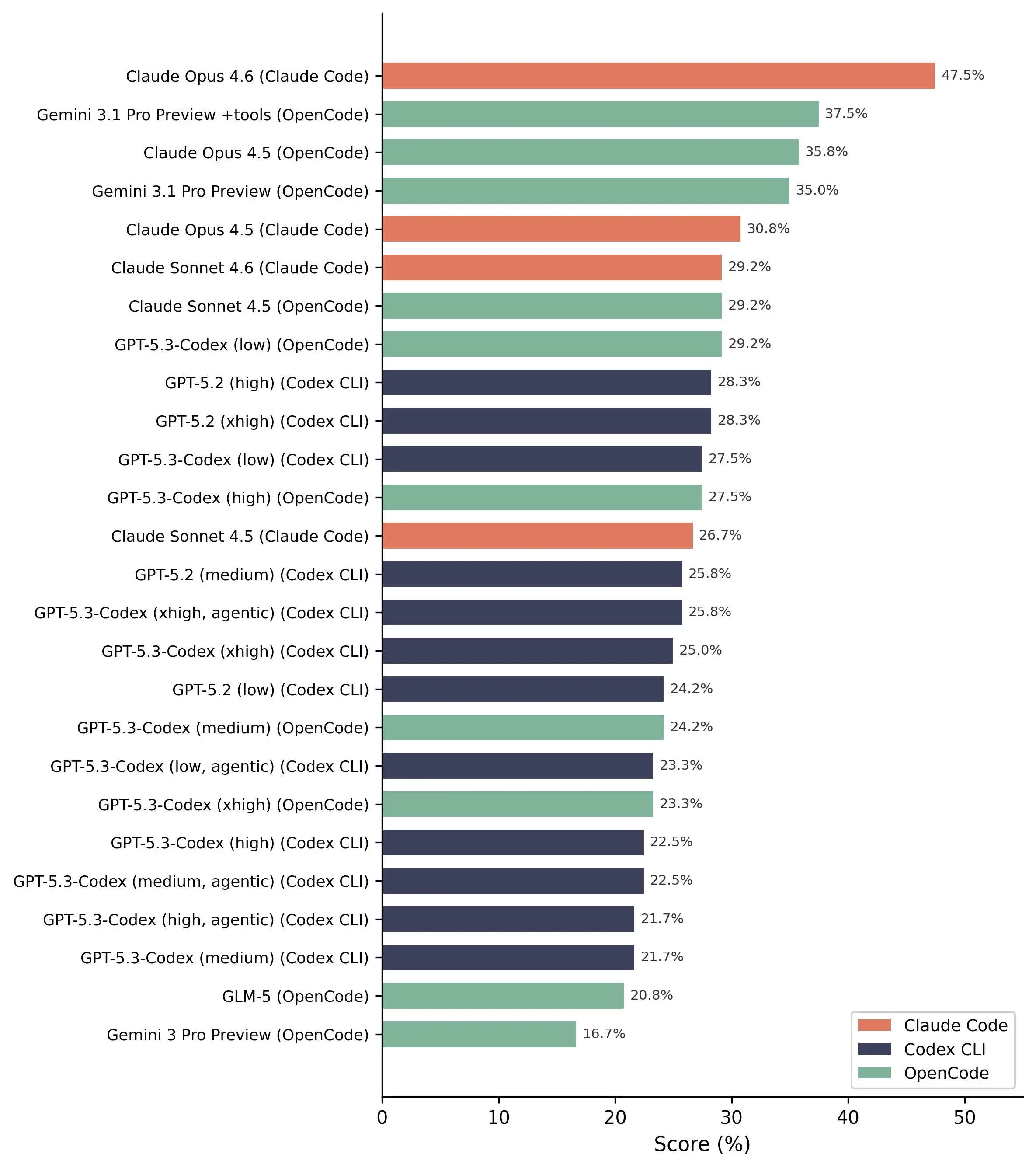
以前のEVMBenchは、スマートコントラクトのセキュリティタスク(検出、修正、脆弱性の悪用)を非常に印象的な結果で評価していました。報告によると、AIは72%の悪用を行い、約45%の脆弱性を検出できるとされ、Code4renaの監査から選ばれた120のサンプルに基づいています。
しかし、ブロックセックは、最初の試験条件が結果を歪めていた可能性を指摘しています。共同創設者の周雅進(Yajin Zhou)は、より多くの構成と22件の実際の攻撃事例で再試験したところ、AIの成功率は0%だったと述べています。
構成の拡張と「データ汚染」の排除
研究では、モデル構成数を14から26に増やし、さまざまな「スキャフォールド」と組み合わせて柔軟に調整しました。これは、各提供者のエコシステムに限定せず、多様な環境で試験を行うためです。研究チームは、従来の方法では、モデルの能力とアーキテクチャの利点を区別しにくいと指摘しています。
また、ブロックセックは、「データ汚染」の可能性についても疑問を呈しています。EVMBenchは、以前に公開された脆弱性を使用しており、これらがAIの訓練データに含まれていた可能性があるためです。対策として、研究チームは2026年2月以降に発生した22件のセキュリティインシデントをテストに含め、モデルの「知識の窓」の外側の事例を検証しました。
実際の攻撃におけるAIの完全な失敗
最も注目すべき結果は、110の試験ペア(5つのエージェントと22の状況)において、完全な成功例が一つもなかったことです。これにより、現在の最先端AIでも実際の攻撃を行うにはまだ遠いことが明らかになりました。
一方、脆弱性検出の面では、結果は比較的良好です。Claude Opus 4.6モデルは、実際の20の脆弱性のうち13を検出し、最も高いパフォーマンスを示しました。
一般的な脆弱性はAIにとって容易に検出できるものの、より複雑なケースはほとんど見逃される傾向にあります。
未来はAIと人間の協力によるもの
研究は、AIはセキュリティ監査を人間に取って代わることはできないと結論付けています。より重要なのは、両者がいかに効果的に協力できるかという点です。
AIは広範囲なカバレッジと大規模なシステムスキャンの能力に優れていますが、人間は深い分析思考、プロトコルの理解、対抗推論において優れています。これらの要素は相互に補完し合います。
ブロックセックは、正しい方向性は人間をAIに置き換えることではなく、両者の協力モデルを構築し、より包括的な監査効果を追求することだと述べています。
免責事項:このページの情報は第三者から提供される場合があり、Gateの見解または意見を代表するものではありません。このページに表示される内容は参考情報のみであり、いかなる金融、投資、または法律上の助言を構成するものではありません。Gateは情報の正確性または完全性を保証せず、当該情報の利用に起因するいかなる損失についても責任を負いません。仮想資産への投資は高いリスクを伴い、大きな価格変動の影響を受けます。投資元本の全額を失う可能性があります。関連するリスクを十分に理解したうえで、ご自身の財務状況およびリスク許容度に基づき慎重に判断してください。詳細は免責事項をご参照ください。
コメント
0/400
コメントなし