

Meta11
現在、コンテンツはありません
Meta11
インフラの本質は、複雑な物事を簡単にすることです。
しかし、ほとんどのインフラは正反対のことをしています。
彼らは簡単なことを複雑にした🤣
データを保存したいですか?プロトコルを選択してください
スマートコントラクトにデータを読み取らせたいですか?別のプロトコルを選択してください。
両者を同じネットワーク上で実行したいですか?ブリッジとリレーが必要です。
@irys_xyzの方法は全く異なります:開発者がインフラの制約に適応することを要求するのではなく、インフラが開発者のニーズに適応するようにします。
—————————————————————————
従来の思考は階層構造です:ストレージ層、実行層、アプリケーション層がそれぞれの役割を果たします。
データが異なるプロトコル間で流れるとき、コンテキストが失われ、スマートコントラクトは基盤データを直接検証できず、開発者は複数の統合ソリューションを維持する必要があります。
IrysのIrysVMは、データストレージとスマートコントラクトの実行を同一のバーチャルマシン内でネイティブに行い、クロスプロトコル呼び出しのオーバーヘッドと複雑さを排除します。
—————————————————————————
"プログラム可能なデータ"はマーケティング用語のように聞こえますが、その背後にある論理は明確です:
データはもはや静的に保存された情報の
原文表示しかし、ほとんどのインフラは正反対のことをしています。
彼らは簡単なことを複雑にした🤣
データを保存したいですか?プロトコルを選択してください
スマートコントラクトにデータを読み取らせたいですか?別のプロトコルを選択してください。
両者を同じネットワーク上で実行したいですか?ブリッジとリレーが必要です。
@irys_xyzの方法は全く異なります:開発者がインフラの制約に適応することを要求するのではなく、インフラが開発者のニーズに適応するようにします。
—————————————————————————
従来の思考は階層構造です:ストレージ層、実行層、アプリケーション層がそれぞれの役割を果たします。
データが異なるプロトコル間で流れるとき、コンテキストが失われ、スマートコントラクトは基盤データを直接検証できず、開発者は複数の統合ソリューションを維持する必要があります。
IrysのIrysVMは、データストレージとスマートコントラクトの実行を同一のバーチャルマシン内でネイティブに行い、クロスプロトコル呼び出しのオーバーヘッドと複雑さを排除します。
—————————————————————————
"プログラム可能なデータ"はマーケティング用語のように聞こえますが、その背後にある論理は明確です:
データはもはや静的に保存された情報の

- 報酬
- いいね
- コメント
- リポスト
- 共有
Dappがデータを漏らさずにデータを証明できるとき、それは隠された超能力を発見したような感覚です 🤯
従来のスマートコントラクトは「記憶喪失」に陥り、履歴を記憶できず、クロスチェーン分析ができず、複雑な計算を処理できません。ユーザーの履歴行動データを取得するには、中央集権的なインデックスサービスに依存するか、高額なガスコストに直面する必要があります。
DeFiプロトコルは現在の状態に基づいて意思決定を行うしかなく、ユーザーの完全な行動プロファイルに基づく正確なリスク管理の機会を逃しています。
@brevis_zk 的创新
—————————————————————————
ZKコプロセッサは「不可能」を「日常の操作」に変えます
オフチェーンで複雑な計算を実行 → ZK証明を生成 → チェーン上で結果を検証
プロトコルは、ユーザーのEth、Arb、Polygonでの完全な取引履歴を分析できる一方で、情報が漏洩しないように保護します。
アプリケーションシーン
—————————————————————————
zkBridge:ZK証明を使用してクロスチェーンの状態を直接検証し、マルチシグの信頼依存を脱却する
DeFi:歴史的な取引パターンに基づくスマートリスク管理とダイナミックプライシング
zkDID:複数のチェーンの行動データを統合し、統一された身分証明を生成します。
AIアプリ
原文表示従来のスマートコントラクトは「記憶喪失」に陥り、履歴を記憶できず、クロスチェーン分析ができず、複雑な計算を処理できません。ユーザーの履歴行動データを取得するには、中央集権的なインデックスサービスに依存するか、高額なガスコストに直面する必要があります。
DeFiプロトコルは現在の状態に基づいて意思決定を行うしかなく、ユーザーの完全な行動プロファイルに基づく正確なリスク管理の機会を逃しています。
@brevis_zk 的创新
—————————————————————————
ZKコプロセッサは「不可能」を「日常の操作」に変えます
オフチェーンで複雑な計算を実行 → ZK証明を生成 → チェーン上で結果を検証
プロトコルは、ユーザーのEth、Arb、Polygonでの完全な取引履歴を分析できる一方で、情報が漏洩しないように保護します。
アプリケーションシーン
—————————————————————————
zkBridge:ZK証明を使用してクロスチェーンの状態を直接検証し、マルチシグの信頼依存を脱却する
DeFi:歴史的な取引パターンに基づくスマートリスク管理とダイナミックプライシング
zkDID:複数のチェーンの行動データを統合し、統一された身分証明を生成します。
AIアプリ

- 報酬
- いいね
- コメント
- リポスト
- 共有
従来の手法では、BTCをWBTCに包み、流動性が他のネットワークに分散されます。ユーザーはブリッジのリスクを負い、資産はビットコインのエコシステムから離れ、その安全性が希薄化します。 @ArchNtwrk はゲームのルールを変えようとしています。
テクノロジーのブレークスルー
—————————————————————————
ArchVMは拡張されたeBPF仮想マシンに基づいており、UTXOモデルをネイティブに理解します。ラッピングやブリッジは不要で、ビットコインの基盤層で直接スマートコントラクトを実行します。
FROST + ROAST閾値署名スキームは、バリデーターがビットコインの取引を共同で制御できるようにし、単一の主体を信頼する必要がありません。dPoSコンセンサスはオンチェーン活動を調整し、すべての状態は直接ビットコインL1にアンカーされています。
予確認システムはビットコインの10分ブロック生成制限を突破し、ア秒レベルの応答を実現しました。ユーザー体験はソラナに匹敵し、安全性はビットコインを継承しています。
アプリケーション再構築
————————————————————————
DeFiプロトコルは、合成資産ではなく、実際のBTCを担保として直接使用できます。AMM、貸出プロトコル、ステーブルコインは、ビットコインのネイティブ環境で動作します。
RWAトークンは直接
原文表示テクノロジーのブレークスルー
—————————————————————————
ArchVMは拡張されたeBPF仮想マシンに基づいており、UTXOモデルをネイティブに理解します。ラッピングやブリッジは不要で、ビットコインの基盤層で直接スマートコントラクトを実行します。
FROST + ROAST閾値署名スキームは、バリデーターがビットコインの取引を共同で制御できるようにし、単一の主体を信頼する必要がありません。dPoSコンセンサスはオンチェーン活動を調整し、すべての状態は直接ビットコインL1にアンカーされています。
予確認システムはビットコインの10分ブロック生成制限を突破し、ア秒レベルの応答を実現しました。ユーザー体験はソラナに匹敵し、安全性はビットコインを継承しています。
アプリケーション再構築
————————————————————————
DeFiプロトコルは、合成資産ではなく、実際のBTCを担保として直接使用できます。AMM、貸出プロトコル、ステーブルコインは、ビットコインのネイティブ環境で動作します。
RWAトークンは直接

- 報酬
- いいね
- コメント
- リポスト
- 共有
AIの突破はより大きなモデルではなく、より良いコンピューティングパワーにあります。
コンピューティングパワーは少数の巨頭によって独占されており、彼らが誰が革新できるか、コストがどのようになるかを決定しています。
その結果、AIのイノベーションは行き詰まっています。 ソリューション:ComputeFi
👇 詳細情報
—————————————————————————
ComputeFiは、@cysic_xyz上のすべてに革命をもたらします。
分散型インフラストラクチャを通じて、未使用のGPUとCPUをグローバルに検証可能なコンピューティングパワー経済に変換する。
雲のようにスケーラブル
暗号化による検証が可能
誰でもアクセスできます
ComputeFiはオープンで、検証可能で、境界のないコンピューティングパワーを提供します。
ガードマンもボトルネックもいない。
—————————————————————————
従来のクラウドコンピューティングの問題は信頼の依存です。ユーザーはAWSやGoogle Cloudが計算タスクを正しく実行することを信じなければなりません。
CysicのComputeFiは、ZKプルーフを通じて、この信頼の必要性を完全に排除します。
すべての計算結果には数学的証明があり、いかなる仲介者も信頼する必要はありません。
"信頼するが検証する"から"信頼しないが
原文表示コンピューティングパワーは少数の巨頭によって独占されており、彼らが誰が革新できるか、コストがどのようになるかを決定しています。
その結果、AIのイノベーションは行き詰まっています。 ソリューション:ComputeFi
👇 詳細情報
—————————————————————————
ComputeFiは、@cysic_xyz上のすべてに革命をもたらします。
分散型インフラストラクチャを通じて、未使用のGPUとCPUをグローバルに検証可能なコンピューティングパワー経済に変換する。
雲のようにスケーラブル
暗号化による検証が可能
誰でもアクセスできます
ComputeFiはオープンで、検証可能で、境界のないコンピューティングパワーを提供します。
ガードマンもボトルネックもいない。
—————————————————————————
従来のクラウドコンピューティングの問題は信頼の依存です。ユーザーはAWSやGoogle Cloudが計算タスクを正しく実行することを信じなければなりません。
CysicのComputeFiは、ZKプルーフを通じて、この信頼の必要性を完全に排除します。
すべての計算結果には数学的証明があり、いかなる仲介者も信頼する必要はありません。
"信頼するが検証する"から"信頼しないが

- 報酬
- いいね
- コメント
- リポスト
- 共有
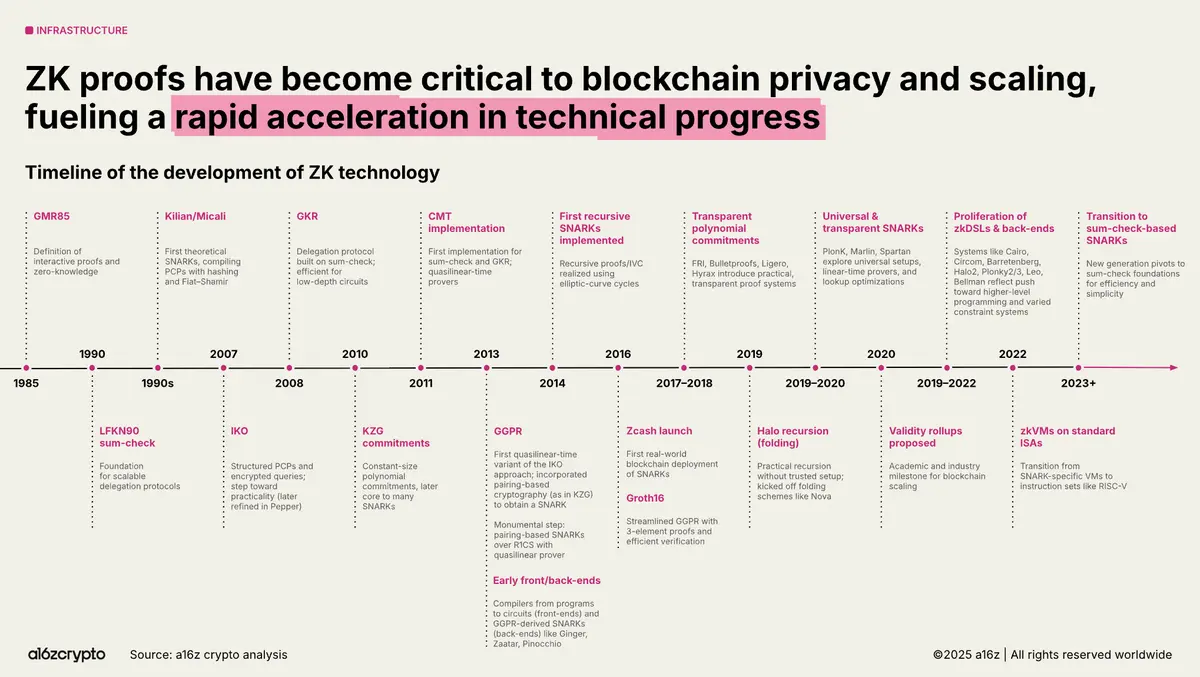
ZKはもはや二者択一の技術的アプローチではなく、プライバシー、スケーラビリティ、安全性という三つの核心的な問題を同時に解決する統一されたソリューションです。
皆がZK証明がプライバシーツールなのか、スケーリングソリューションなのかを議論している間に、真の変革は既に始まっています。 @cysic_xyz は、証明可能な計算を概念から実際の生産へと推進しています。高価な生成プロセスを検証可能なネットワークにアウトソーシングし、検証コストを十分に低く抑えています。
過去、ZKは「高すぎる、遅すぎる」と見なされており、ボトルネックは主に証明生成にありました。
現在、専用証明の加速(GPU/FPGA/ASIC)により、生成時間が大幅に短縮されています。開発者は必要に応じて計算力を呼び出して証明を行います。
Cysicの切り口は、証明生成を検証可能な公共サービスにすることであり、アプリケーション側は独自に証明クラスターを構築する必要がありません。証明の正当性は暗号学によって保証され、信頼の境界はプロトコル自体に戻ります。
つまり、Rollup、プライバシー決済、アイデンティティおよびコンプライアンスなどのシナリオは、より確実なコストでオンラインにでき、証明生成によってオンラインのリズムが妨げられることはありません。
証明の生成と検証は帯域幅やストレージのように即座に利用可能になります。
開発者
原文表示皆がZK証明がプライバシーツールなのか、スケーリングソリューションなのかを議論している間に、真の変革は既に始まっています。 @cysic_xyz は、証明可能な計算を概念から実際の生産へと推進しています。高価な生成プロセスを検証可能なネットワークにアウトソーシングし、検証コストを十分に低く抑えています。
過去、ZKは「高すぎる、遅すぎる」と見なされており、ボトルネックは主に証明生成にありました。
現在、専用証明の加速(GPU/FPGA/ASIC)により、生成時間が大幅に短縮されています。開発者は必要に応じて計算力を呼び出して証明を行います。
Cysicの切り口は、証明生成を検証可能な公共サービスにすることであり、アプリケーション側は独自に証明クラスターを構築する必要がありません。証明の正当性は暗号学によって保証され、信頼の境界はプロトコル自体に戻ります。
つまり、Rollup、プライバシー決済、アイデンティティおよびコンプライアンスなどのシナリオは、より確実なコストでオンラインにでき、証明生成によってオンラインのリズムが妨げられることはありません。
証明の生成と検証は帯域幅やストレージのように即座に利用可能になります。
開発者
- 報酬
- いいね
- コメント
- リポスト
- 共有
SentientはOpen AGI Summitのスポンサーを発表した。AWS、Polygon、EigenLayerといったインフラストラクチャの巨人と並んで公式パートナーとなり、分散化AI分野における彼らの戦略的地位を十分に示している。
検証可能な推論、分散化推論の加速、データ貢献とインセンティブメカニズムなどの面で、@SentientAGIのスタックはこれらのインフラストラクチャと技術的共鳴を形成し、「計算力-モデル-決済」の三層クローズドループを推進します。
Sentientは分散化されたAIネットワークを構築しており、大量の開発者、研究者、インフラパートナーが必要です。Open AGI Summitは最も直接的な接触チャネルを提供します。
Dobby-70Bが推論ノードと共に現場で稼働し、オープン評価を通じて品質-遅延-コスト曲線を示すと、現場の各プロジェクトは潜在的な統合者およびノードオペレーターになる可能性があります。モデルが多くのシーンで実現され、ノードが増え、データとフィードバックが豊富になるほど、モデルとエージェントフレームワークにさらにフィードバックを行い、正のフィードバックループを形成します。
Sentientは3つの事を閉じたループにします:
1) モデルとエージェント:Dobby-70Bおよびその指示/マルチモーダル変種は、実際のAgentシナリオを中心に
原文表示検証可能な推論、分散化推論の加速、データ貢献とインセンティブメカニズムなどの面で、@SentientAGIのスタックはこれらのインフラストラクチャと技術的共鳴を形成し、「計算力-モデル-決済」の三層クローズドループを推進します。
Sentientは分散化されたAIネットワークを構築しており、大量の開発者、研究者、インフラパートナーが必要です。Open AGI Summitは最も直接的な接触チャネルを提供します。
Dobby-70Bが推論ノードと共に現場で稼働し、オープン評価を通じて品質-遅延-コスト曲線を示すと、現場の各プロジェクトは潜在的な統合者およびノードオペレーターになる可能性があります。モデルが多くのシーンで実現され、ノードが増え、データとフィードバックが豊富になるほど、モデルとエージェントフレームワークにさらにフィードバックを行い、正のフィードバックループを形成します。
Sentientは3つの事を閉じたループにします:
1) モデルとエージェント:Dobby-70Bおよびその指示/マルチモーダル変種は、実際のAgentシナリオを中心に

- 報酬
- いいね
- コメント
- リポスト
- 共有
従来のデータストレージは、ファイルを「ブラックホール」に投げ込むようなもので、使用するには他のシステムを呼び出さなければなりません。しかし、データが @irys_xyz に保存されると、状況はまったく異なります。
データはもはや静的ファイルではなく、直接ロジックを実行し、権限を管理し、プロセスを自動化するスマートユニットです。これが「Silent data. Because when data is on Irys, it can talk」の真の意味です。
プログラム可能なデータ
—————————————————————————
従来のストレージ:データ + 外部システム処理
Irysモード:データ自体が実行可能なプログラムです
Irysにデータを保存する際、データレベルで権限管理、課金ルール、配信ロジックを直接書き込むことができます。スマートコントラクトはデータを直接呼び出すことができ、データはクエリや実行命令に能動的に応答することができます。
単なるデータストレージではなく、データを実行能力を持つスマートアセットにアップグレードすることです。
ロジックを実現する
—————————————————————————
二重帳簿アーキテクチャ:
レジャーを提出:迅速な検証、並べ替え
パブリッシュレジャー:永続的な保存、追跡可能
リアルタイムの応答を保証するだけでなく、データの完全
原文表示データはもはや静的ファイルではなく、直接ロジックを実行し、権限を管理し、プロセスを自動化するスマートユニットです。これが「Silent data. Because when data is on Irys, it can talk」の真の意味です。
プログラム可能なデータ
—————————————————————————
従来のストレージ:データ + 外部システム処理
Irysモード:データ自体が実行可能なプログラムです
Irysにデータを保存する際、データレベルで権限管理、課金ルール、配信ロジックを直接書き込むことができます。スマートコントラクトはデータを直接呼び出すことができ、データはクエリや実行命令に能動的に応答することができます。
単なるデータストレージではなく、データを実行能力を持つスマートアセットにアップグレードすることです。
ロジックを実現する
—————————————————————————
二重帳簿アーキテクチャ:
レジャーを提出:迅速な検証、並べ替え
パブリッシュレジャー:永続的な保存、追跡可能
リアルタイムの応答を保証するだけでなく、データの完全
- 報酬
- いいね
- コメント
- リポスト
- 共有
今年の10ヶ月だけで、数百社のクラウドストレージが攻撃されました。
SalesforceのOAuthトークンが盗まれ、Google、Allianz、Cloudflareなどの大手企業に影響を与えました。
SonicWallのクラウドバックアップシステムが侵害され、Ascension医療システムのサードパーティクラウドプラットフォームが敏感な患者情報を漏洩しました。
すべての侵害は同じストーリーであり、一元化された単一障害点です。
—————————————————————————
AWSやGoogle Cloudといった巨人にデータを預けることは、本質的には賭けをしていることになる。安全対策が決して失敗しないことを賭け、ハッカーが決して脆弱性を見つけないことを賭け、第三者の供給者が決して突破口にならないことを賭けている。
しかし現実は、中央集権的なクラウドサービスはハッカーの蜜罠である。一度突破されれば、データはすべて暴露される。
@cysic_xyz ComputeFiは計算とストレージを世界中の数千のノードに分散させ、この問題を効果的に解決できます。
攻撃できる単一のサーバーはありません。
中央データベースは盗まれることがありません。
企業はあなたのアクセス権を閉じることはできません。
各計算タスクはゼロ知識証明によって検証され、結果の正確性を確保しながらデータのプライバシーを
原文表示SalesforceのOAuthトークンが盗まれ、Google、Allianz、Cloudflareなどの大手企業に影響を与えました。
SonicWallのクラウドバックアップシステムが侵害され、Ascension医療システムのサードパーティクラウドプラットフォームが敏感な患者情報を漏洩しました。
すべての侵害は同じストーリーであり、一元化された単一障害点です。
—————————————————————————
AWSやGoogle Cloudといった巨人にデータを預けることは、本質的には賭けをしていることになる。安全対策が決して失敗しないことを賭け、ハッカーが決して脆弱性を見つけないことを賭け、第三者の供給者が決して突破口にならないことを賭けている。
しかし現実は、中央集権的なクラウドサービスはハッカーの蜜罠である。一度突破されれば、データはすべて暴露される。
@cysic_xyz ComputeFiは計算とストレージを世界中の数千のノードに分散させ、この問題を効果的に解決できます。
攻撃できる単一のサーバーはありません。
中央データベースは盗まれることがありません。
企業はあなたのアクセス権を閉じることはできません。
各計算タスクはゼロ知識証明によって検証され、結果の正確性を確保しながらデータのプライバシーを

- 報酬
- いいね
- コメント
- リポスト
- 共有
現在のAIの発展の本当のボトルネックはアルゴリズムではなく、インフラの独占と資源配分の不公平です。
—————————————————————————
従来のAI開発はコアのボトルネックに閉じ込められています:
計算資源の独占:大手テクノロジー企業が世界の大部分の算力を支配しており、革新者は彼らのゲームルールに屈服するか、まったく参加する機会がない。モデルを訓練したい?まずAWSがリソースを提供してくれるかどうかを尋ねてみてください。
モデルの所有権があいまい:オープンソースモデルは明確な所有権構造が欠如しており、価値配分メカニズムが不透明で、貢献者は公平な報酬を得ることができません。
中央集権的な決定:AIの発展方向は少数の企業によって決定され、コミュニティのニーズと価値観が無視される。
これが @SentientAGI が分散型AGIプロトコルを構築する理由です。
OMLフレームワークの突破
—————————————————————————
Open:モデルはオープンソースでなければならず、コードとデータ構造は透明であり、コミュニティによる複製、監査、フォークをサポートする必要があります。
マネタイズ可能:モデルの呼び出しごとに収益ストリームが発生し、オンチェーン契約を通じてトレーナー、デプロイヤー、バリデーターに配分されます。
Loyal:モデルは企業ではなく、貢献者コミュ
—————————————————————————
従来のAI開発はコアのボトルネックに閉じ込められています:
計算資源の独占:大手テクノロジー企業が世界の大部分の算力を支配しており、革新者は彼らのゲームルールに屈服するか、まったく参加する機会がない。モデルを訓練したい?まずAWSがリソースを提供してくれるかどうかを尋ねてみてください。
モデルの所有権があいまい:オープンソースモデルは明確な所有権構造が欠如しており、価値配分メカニズムが不透明で、貢献者は公平な報酬を得ることができません。
中央集権的な決定:AIの発展方向は少数の企業によって決定され、コミュニティのニーズと価値観が無視される。
これが @SentientAGI が分散型AGIプロトコルを構築する理由です。
OMLフレームワークの突破
—————————————————————————
Open:モデルはオープンソースでなければならず、コードとデータ構造は透明であり、コミュニティによる複製、監査、フォークをサポートする必要があります。
マネタイズ可能:モデルの呼び出しごとに収益ストリームが発生し、オンチェーン契約を通じてトレーナー、デプロイヤー、バリデーターに配分されます。
Loyal:モデルは企業ではなく、貢献者コミュ
AGI17.09%

- 報酬
- いいね
- コメント
- リポスト
- 共有
ストレージプロジェクトの大多数は、シンプルで粗野な設計です。ファイルを直接チェーンに投げるか、完全にオフチェーンに留めるかのどちらかで、スイッチのように非白即黒です。しかし、現実世界のデータは、一度決まった形になるものではありません。
それは最初に提出され、次に確認され、変更される可能性があり、異なる役割の確認を経て、最後に永久に保存または公開される必要があります。
一発で済むように聞こえるが、実際にはこれらの中間プロセスを収容できない。
サイクル解体
—————————————————————————
@irys_xyz マルチレジャーはデータライフサイクルを異なるステージに分解します:
Ledgerの提出:データ提出の意図を記録し、タイムスタンプと署名を付与する
Publish Ledger:データは検証され、永久にオフチェーンに記録されました。
拡張レイヤー:コミュニティガバナンス、特定分野のルールまたはユースケースロジックをサポート
これはデータの実際の流動経路の復元です。
去中心化アートコンペティションを想像してみてください
アーティストは作品をSubmit Ledgerに提出します
コミュニティ投票の検証は、オフチェーンまたはDAOガバナンスで行うことができます
入賞したエントリーは、Publish Ledgerに公開されます
全てのプロセスは透明で追跡可能であり、各段
原文表示それは最初に提出され、次に確認され、変更される可能性があり、異なる役割の確認を経て、最後に永久に保存または公開される必要があります。
一発で済むように聞こえるが、実際にはこれらの中間プロセスを収容できない。
サイクル解体
—————————————————————————
@irys_xyz マルチレジャーはデータライフサイクルを異なるステージに分解します:
Ledgerの提出:データ提出の意図を記録し、タイムスタンプと署名を付与する
Publish Ledger:データは検証され、永久にオフチェーンに記録されました。
拡張レイヤー:コミュニティガバナンス、特定分野のルールまたはユースケースロジックをサポート
これはデータの実際の流動経路の復元です。
去中心化アートコンペティションを想像してみてください
アーティストは作品をSubmit Ledgerに提出します
コミュニティ投票の検証は、オフチェーンまたはDAOガバナンスで行うことができます
入賞したエントリーは、Publish Ledgerに公開されます
全てのプロセスは透明で追跡可能であり、各段
- 報酬
- いいね
- コメント
- リポスト
- 共有