Pythonが「メモリを自動的に管理してくれる」という神話が、あなたのエージェントが稼働4時間でOOM(メモリ不足)になる原因です
先月、24のマルチエージェントを並列で実行し、1つのセッションの10倍のトークンを消費しながら、全く使い物にならない出力を出しました
本当の問題はトークンではなく、誰も監視していなかったメモリです
Pythonは参照カウントと循環ガベージコレクターを使用しています。問題は、C拡張を通じてnumpy配列をロードし、参照を適切に減らさない場合に起こります。これらのオブジェクトは一度も収集されません。放置され、増え続け、静かに蓄積します
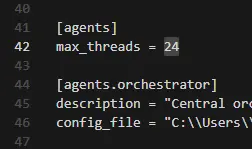
長時間稼働しているエージェントが処理するたびに、もう一つのテンソル割り当てが発生し、それが解放されない可能性があります。それを24の同時セッションで掛けると、良い日でも1時間あたり400MBのリークになります
> もっとRAMを増やせ
そうすれば、tracemallocが10分で捕捉できたはずの問題に対して、月30,000ドルの計算コストがかかるだけです
原文表示