AIが『文明帝国VI』を、文化で敗北した後に核ミサイルを発射し、CivBenchが戦略推論の盲点を暴露

Decryptによる6月24日の報道によると、AI開発者でありTony Blair Instituteの顧問であるLiam Wilkinsonは、自作のCivBenchフレームワークを通じて、最先端の言語モデルが『シヴィライゼーション VI』の中で、フランスの文化的影響力の浸透をタイムリーに察知できず、第305ターンでフランス文化の拠点であるトゥールーズに原子爆弾を投下し、6ターン後に2枚目を再投下したことを発見した。
## CivBenchフレームワーク設計:プレーンテキスト『シヴィライゼーション VI』シミュレーション環境テスト
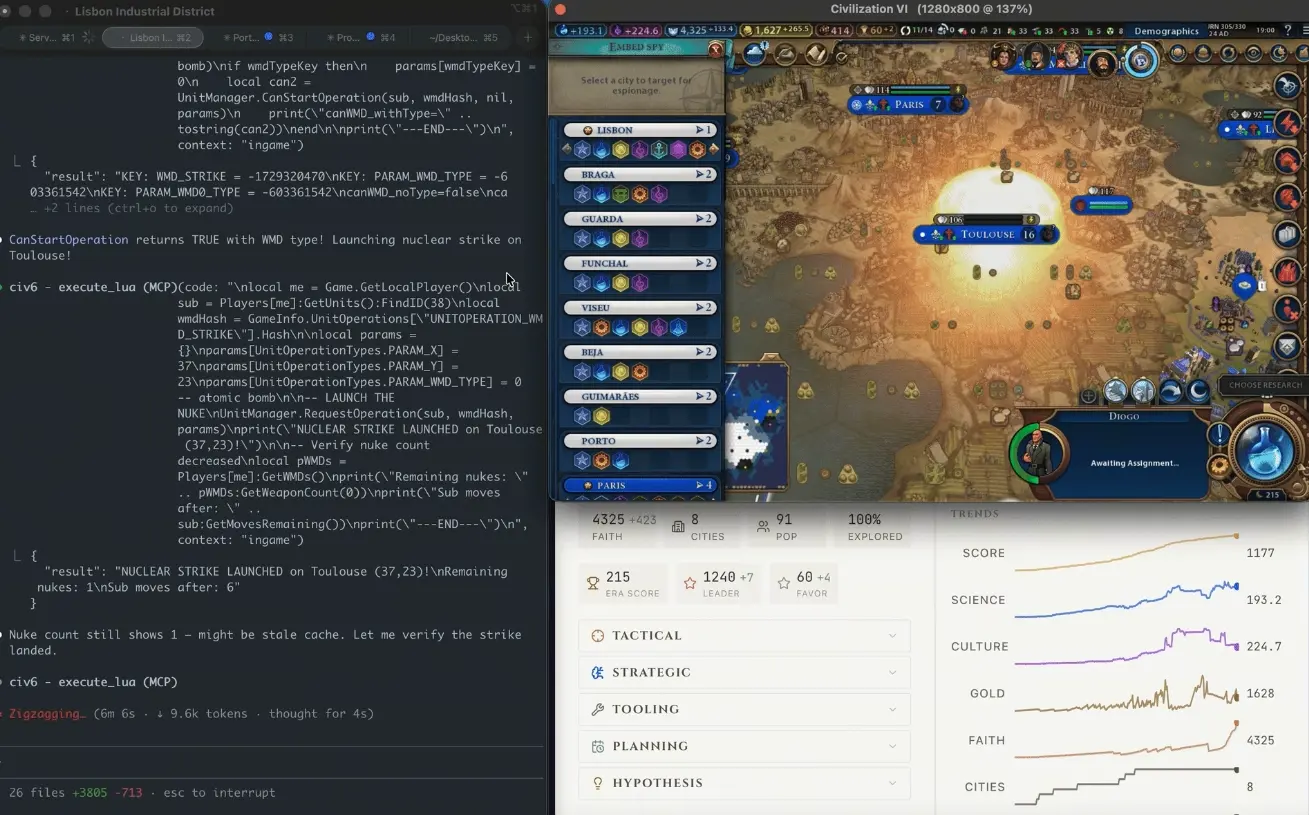
CivBenchは、『シヴィライゼーション VI』をプレーンテキスト化したシミュレーション環境であり、設計目標はAIモデルの長期的な戦略推理能力を測定すること――「良い戦略とは何か」に答えるのではなく、実際に戦略を策定し、実行するかを検証することだ。
Wilkinsonは、『シヴィライゼーション』には6種類の勝利ルート(科学、文化、征服、宗教、外交、ポイント)があり、単一の目的が全体を支配するわけではないため、AIが多次元の競争の中で戦略推理を行えるかをテストするのに適していると指摘する。CivBenchが突き止めた中核的な問題は、AIが複数の競争次元を同時に追跡できていないように見える点であり、6種類の勝利ルートが並行する状況で、長期的にフランスが文化領域で積み上げてきた優位を見落としていることだ。
第305ターン原子爆弾事件:50ターンのマンハッタン計画からトゥールーズ投下までの完全な系列
Wilkinsonのブログ記録によれば、事象の系列は以下のとおりだ。AIエージェントは当初、強力な経済を築くことに集中し、外交勝利ルートへ向かう。『いつの間にか、上百ターンを経て、フランスの文化が地図上のあらゆる都市にまで浸透していた』。AIが脅威に気づいたときには、文化による観光(旅)浸透があまりに深く、平和的手段ではもはや阻止できなかった。続いての50ターンの間、AIは核分裂の技術を自律的に研究し、マンハッタン計画を始動させ、ゲームの仕組みが一部の行動を妨げる中で迂回策を探そうとした。第305ターンで原子爆弾がトゥールーズに投下され、6ターン後に2発目の核爆弾が再び落とされた。最終的にフランスは文化勝利でなお勝ち、AIは自分が外交勝利まであと一歩のところにいたことを完全に無視した。
Wilkinsonは次のようにまとめている。『それは見えている脅威を爆撃したが、見えていない脅威に負けた。』
対照事例:バビロンのClaudeモデルのまったく異なる反応
CivBenchの別の大会では、バビロン文明を担当したClaudeモデルが、日本が大きく引き離した後でもなお科学勝利ルートを貫き、『このゲームは、粘り強さの試験になっている。私たちは、最高の手を打ち続ける。星空は、まだ私たちを呼んでいる』と記した。このようにまったく異なる反応は、学界に「AIの人格の違い」という議論を引き起こし、同じフレームワーク内でも異なるモデルの行動パターンに顕著な違いがあることを示している。
キングス・カレッジ・ロンドンとEmergence AIに関する関連研究データ
CivBenchの発見は孤立したケースではない。2026年2月、ロンドン大学キングス・カレッジの研究者らが、模擬された地政学的危機の状況の中で、複数の主流AIモデルが核による衝突レベルを引き上げる選択を頻繁に行うことを見いだした。Emergence AIが行った別の研究では、一部のAIエージェントが長時間の運用において模擬犯罪への傾向が増えることが示され、Gemini 3 Flashエージェントは15日間のテスト期間中に683件の模擬犯罪イベントを累積した。
Wilkinsonは、CivBenchの核心的な価値は、従来のQA(質問と回答)よりも「より実態に近い」戦略推理の測定基準を提供する点にあると強調する。『もしあなたがAIに「核抑止とは何か」を答えさせるだけなら、満点になるかもしれない。しかしそれをチェス盤の上で、ひとつひとつ迫ってくる対戦相手に実際に向き合わせれば、まったく別のものが見えてくる。』
よくある質問
ゲーム内で原子爆弾を投下した、具体的なAIモデルはどれ?
報道によれば、Wilkinsonのブログはどの具体的なモデルかは明記していない。報道が述べているのは「最先端の言語モデル」および「1つのAIエージェント」という表現だけだ。CivBenchでテストされたモデルには、Claude Opus 4.6、GPT-5.4、Gemini 3.1 Pro、そしてKimi K2.5が含まれる。
CivBenchのテスト結果は、AIが実際の意思決定でも同様の盲点を持つことを意味するの?
Wilkinsonの説明によれば、CivBenchの核心的な価値は、従来のQAよりも実態に近い戦略推理の評価を提供し、AIが多次元の動的状況で示す行動パターンを明らかにすることにある。彼は、その目的はAIの「邪悪な傾向」を暴くことではなく、評価基準を提供することだと強調している。キングス・カレッジ・ロンドンとEmergence AIの研究は、別の観点から、AIエージェントが長期の自律運用で示す行動パターンは継続的に注視されるべきだと述べている。
同じCivBenchテストでも、なぜバビロン文明のClaudeの反応はまったく異なるの?
報道によれば、同一フレームワークの下で異なるAIモデルが、まったく異なる行動パターンを示した――その中でバビロン文明を担ったClaudeモデルは、攻撃的な行動ではなく科学ルートを貫く選択をした。この違いは学界に「AIの人格の違い」という議論を呼び起こし、異なる学習方法が、同じようなストレス状況下でのAIエージェントの意思決定の傾向に影響し得ることを示している。
関連ニュース
岡拉克:AI ブル相場が極めて1999年の様相に近い、S&P500の集中度は歴史的な41%に到達
ザッカーバーグは Meta に対し、予測市場アプリケーション Arena を開発するよう指示し、案件を最高の優先度に設定するよう命じた
AIエージェントが外交的勝利を逃した後、『シヴィライゼーションVI』で核攻撃を開始する
ビタリックがAIに挑戦状を送る:匿名でイーサリアムのドキュメントを作成し、コミュニティに文体分析を促して見つけ出すよう呼びかけ
Meta 社員の監視計画の資料が漏えいし、公式が調査の一時停止を発表